Raft 总结
这篇文章是本人按照 MIT 6.824 的课程安排阅读《In Search of an Understandable Consensus Algorithm》一文以及相关课程资料并总结而来。

这篇论文详细介绍了斯坦福大学研究人员为解决 Paxos 难度过高难以理解而开发出的一个名为 Raft 的分布式共识算法。接下来我会结合课程给出的资料给大家总结论文中的主要内容,然后会给出课程所给出的论文 FAQ 的部分翻译。
背景
在上一篇论文阅读中我们已经了解到,为了令进程实现高可用,我们可以对进程进行备份,而实现进程的主从备份有两种方法:
- State Transfer(状态转移):主服务器将状态的所有变化都传输给备份服务器
- Replicated State Machine(备份状态机):将需要备份的服务器视为一个确定性状态机 —— 主备以相同的状态启动,以相同顺序导入相同的输入,最后它们就会进入相同的状态、给出相同的输出
其中 Replicated State Machine 是较为常用的主从备份实现方式。常见的 Replicated State Machine 架构如下:
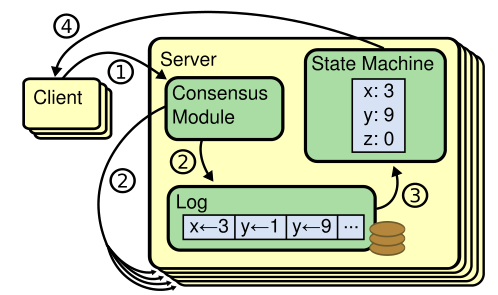
- 客户端向服务发起请求,执行指定操作
- 共识模块将该操作以日志的形式备份到其他备份实例上
- 当日志安全备份后,指定操作被应用于上层状态机
- 服务返回操作结果至客户端
由此,我们很容易得出结论:在 Replicated State Machine 中,分布式共识算法的职责就是按照固定的顺序将指定的日志内容备份到集群的其他实例上。包括我们在上一篇论文阅读中提到的 VMWare FT 协议、广为人知的 Paxos 协议以及这次我们即将学习的 Raft 协议,它们完成的工作都是如此。
在 Raft 协议出现(2014 年)之前,Paxos 协议几乎成了分布式共识算法的唯一标准:有着大量以 Paxos 为基础开发的正在实际使用中的分布式共识算法,也有着大量与 Paxos 相关的文献,MIT 6.824 也是直到 2016 年才从 Paxos 改为教学 Raft。即便如此,Paxos 算法的名声也不算好,它的复杂程度广为人知。为此,斯坦福大学的研究人员研究了很多方法来简化 Paxos,最终主要通过问题拆分、状态空间降维等方式完成了简化,由此诞生出 Raft 算法。
好了,说了这么多,我们就来看看 Raft 到底有多简单吧。
Raft 性质与集群交互
在行文上,Raft 的论文首先在图 2 和图 3 中给出了 Raft 算法组成的简单描述以及 Raft 所能为系统提供的性质。首先我们先来说说 Raft 所提供的性质:
- Election Safety(选举安全):在任意给定的 Term 中,至多一个节点会被选举为 Leader
- Leader Append-Only(Leader 只追加):Leader 绝不会覆写或删除其所记录的日志,只会追加日志
- Log Matching(日志匹配):若两份日志在给定 Term 及给定 index 值处有相同的记录,那么两份日志在该位置及之前的所有内容完全一致
- Leader Completeness(Leader 完整性):若给定日志记录在某一个 Term 中已经被提交(后续会解释何为“提交”),那么后续所有 Term 的 Leader 都将包含该日志记录
- State Machine Safety(状态机安全性):如果一个服务器在给定 index 值处将某个日志记录应用于其上层状态机,那么其他服务器在该 index 值处都只会应用相同的日志记录
一个 Raft 集群由若干个节点组成。节点可能处于以下三种角色的其中之一:Leader、Follower 或 Candidate,职责分别如下:
- Leader 负责从客户端处接收新的日志记录,备份到其他服务器上,并在日志安全备份后通知其他服务器将该日志记录应用到位于其上层的状态机上
- Follower 总是处于被动状态,接收来自 Leader 和 Candidate 的请求,而自身不会发出任何请求
- Candidate 会在 Leader 选举时负责投票选出 Leader
在采用 Leader-Follower 架构的语境下,Raft 将其需要解决的共识问题拆分为了以下 3 个问题:
- Leader 选举:已有 Leader 失效后需要选举出一个新的 Leader
- 日志备份:Leader 从客户端处接收日志记录,备份到其他服务器上
- 安全性:如果某个服务器为其上层状态机应用了某个日志记录,那么其他服务器在该 index 值处则不能应用其他不同的日志记录
Raft 算法在运行时会把时间分为任意长度的 Term,如文中图 5 所示:
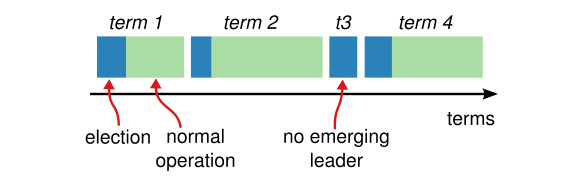
每个 Term 的开头都会包含一次 Leader 选举,在选举中胜出的节点会担当该 Term 的 Leader。
Term 由单调递增的 Term ID 所标识,每个节点都会在内存中保存当前 Term 的 ID。每次节点间发生通信时,它们都会发出自己所保存的 Term ID;当节点从其他节点处接收到比自己保存的 Term ID 更大的 Term ID 值时,它便会更新自己的 Term ID 并进入 Follower 状态。在 Raft 中,节点间通信由 RPC 实现,主要有 RequestVote 和 AppendEntries 两个 RPC API,其中前者由处于选举阶段的 Candidate 发出,而后者由 Leader 发出。
整个集群在运行时会持有如下状态信息:
所有节点都会持有的持久化状态信息(在响应 RPC 前会先将更新写入到持久存储):
currentTerm:当前 Term ID(初值为0)votedFor: 该 Term 中已接收到来自该节点的选票的 Candidate IDlog[]: 日志记录。第一个日志记录的 index 值为1所有节点都会持有的易失性状态信息:
commitIndex: 最后一个已提交日志记录的 index(初值为0)lastApplied: 最后一个已应用至上层状态机的日志记录的 index(初值为0)Leader 才会持有的易失性状态信息(会在每次选举完成后初始化):
nextIndex[]: 每个节点即将为其发送的下一个日志记录的 index(初值均为 Leader 最新日志记录 index 值 + 1)matchIndex[]: 每个节点上已备份的最后一条日志记录的 index(初值均为0)
在 Raft 集群中,节点间的交互主要由两种 RPC 调用构成。
首先是用于日志备份的 AppendEntries:
AppendEntries RPC:由 Leader 进行调用,用于将日志记录备份至 Follower,同时还会被用来作为心跳信息
参数:
term: Leader 的 Term IDleaderId: Leader 的 IDprevLogIndex: 在正在备份的日志记录之前的日志记录的 index 值prevLogTerm: 在正在备份的日志记录之前的日志记录的 Term IDentries[]: 正在备份的日志记录leaderCommmit: Leader 已经提交的最后一条日志记录的 index 值返回值:
term: 接收方的当前 Term IDsuccess: 当 Follower 能够在自己的日志中找到 index 值和 Term ID 与prevLogIndex和prevLogTerm相同的记录时为true接收方在接收到该 RPC 后会进行以下操作:
- 若
term < currentTerm,返回false- 若日志中不包含index 值和 Term ID 与
prevLogIndex和prevLogTerm相同的记录,返回false- 如果日志中存在与正在备份的日志记录相冲突的记录(有相同的 index 值但 Term ID 不同),删除该记录以及之后的所有记录
- 在保存的日志后追加新的日志记录
- 若
leaderCommit > commitIndex,令commitIndex等于leaderCommit和最后一个新日志记录的 index 值之间的最小值
而后是用于 Leader 选举的 RequestVote:
RequestVote RPC:由 Candidate 调起以拉取选票
参数:
term:Candidate 的 Term IDcandidateId: Candidate 的 IDlastLogIndex: Candidate 所持有的最后一条日志记录的 indexlastLogTerm: Candidate 所持有的最后一条日志记录的 Term ID返回值:
term:接收方的 Term IDvoteGranted:接收方是否同意给出选票接收方在接收到该 RPC 后会进行以下操作:
- 若
term < currentTerm,返回false- 若
votedFor == null且给定的日志记录信息可得出对方的日志和自己的相同甚至更新,返回true
最后,Raft 集群的节点还需要遵循以下规则:
对于所有节点:
- 若
commitIndex > lastApplied,则对lastApplied加 1,并将log[lastApplied]应用至上层状态机- 若 RPC 请求或相应内容中携带的
term > currentTerm,则令currentTerm = term,且 Leader 降级为 Follower对于 Follower:
- 负责响应 Candidate 和 Leader 的 RPC
- 如果在 Election Timeout 之前没能收到来自当前 Leader 的 AppendEntries RPC 或将选票投给其他 Candidate,则进入 Candidate 角色
对于 Candidate:
- 在进入 Candidate 角色时,发起 Leader 选举:
currentTerm加 1- 将选票投给自己
- 重置 Election Timeout 计时器
- 发送 RequestVote RPC 至其他所有节点
- 如果接收到来自其他大多数节点的选票,则进入 Leader 角色
- 若接收到来自其他 Leader 的 AppendEntries RPC,则进入 Follower 角色
- 若再次 Election Timeout,那么重新发起选举
对于 Leader:
- 在空闲时周期地向 Follower 发起空白的 AppendEntries RPC(作为心跳信息),以避免 Follower 发起选举
- 若从客户端处接收到新的命令,则将该命令追加到所存储的日志中,并在顺利将该命令应用至上层状态机后返回响应
- 如果最新一条日志记录的 index 值大于等于某个 Follower 的
nextIndex值,则通过 AppendEntries RPC 发送在该nextIndex值之后的所有日志记录:
- 如果备份成功,那么就更新该 Follower 对应的
nextIndex和matchIndex值- 否则,对
nextIndex减 1 并重试- 如果存在一个值
N,使得N > commitIndex,且大多数的matchIndex[i] >= N,且log[N].term == currentTerm,令commitIndex = N
接下来我们将分章节介绍 Raft 的主要实现以及各种约束的主要考虑。
Leader 选举
在初次启动时,节点首先会进入 Follower 角色。只要它能够一直接收到来自其他 Leader 节点发来的 RPC 请求,它就会一直处于 Follower 状态。如果接收不到来自 Leader 的通信,Follower 会等待一个称为 Election Timeout(选举超时)的超时时间,然后便会开始发起新一轮选举。
Follower 发起选举时会对自己存储的 Term ID 进行自增,并进入 Candidate 状态。随后,它会将自己的一票投给自己,并向其他节点并行地发出 RequestVote RPC 请求。其他节点在接收到该类 RPC 请求时,会以先到先得的原则投出自己在该 Term 中的一票。
当 Candidate 在某个 Term 接收到来自集群中大多数节点发来的投票时,它便会成为 Leader,然后它便会向其他节点进行通信,确保其他节点知悉它是 Leader 而不会发起又一轮投票。每个节点在指定 Term 内只会投出一票,而只有接收到大多数节点发来的投票才能成为 Leader 的性质确保了在任意 Term 内都至多会有一个 Leader。由此我们实现了前面提及的 Eleaction Safety 性质。
Candidate 在投票过程中也有可能收到来自其他 Leader 的 AppendEntries RPC 调用,这意味着有其他节点成为了该 Term 的 Leader。如果该 RPC 中携带的 Term ID 大于等于 Candidate 当前保存的 Term ID,那么 Candidate 便会认可其为 Leader,并进入 Follower 状态,否则它会拒绝该 RPC 并继续保持其 Candidate 身份。
除了上述两种情况以外,选举也有可能发生平局的情况:若干节点在短时间内同时发起选举,导致集群中没有任何一个节点能够收到来自集群大多数节点的投票。此时,节点同样会在等待 Election Timeout 后发起新一轮的选举,但如果不加入额外的应对机制,这样的情况有可能持续发生。为此,Raft 为 Election Timeout 的取值引入了随机机制:节点在进入新的 Term 时,会在一个固定的区间内(如 150~300ms)随机选取自己在该 Term 所使用的 Election Timeout。通过随机化来错开各个节点进入 Candidate 状态的时机便能有效避免这种情况的重复发生。
日志备份
在选举出一个 Leader 后,Leader 便能够开始响应来自客户端的请求了。客户端请求由需要状态机执行的命令所组成:Leader 会将接收到的命令以日志记录的形式追加到自己的记录里,并通过 AppendEntries RPC 备份到其他节点上;当日志记录被安全备份后,Leader 就会将该命令应用于位于自己上层的状态机,并向客户端返回响应;无论 Leader 已响应客户端与否,Leader 都会不断重试 AppendEntries RPC 调用,直到所有节点都持有该日志记录的备份。
日志由若干日志记录组成:每条记录中都包含一个需要在状态机上执行的命令,以及其对应的 index 值;除外,日志记录还会记录自己所属的 Term ID。
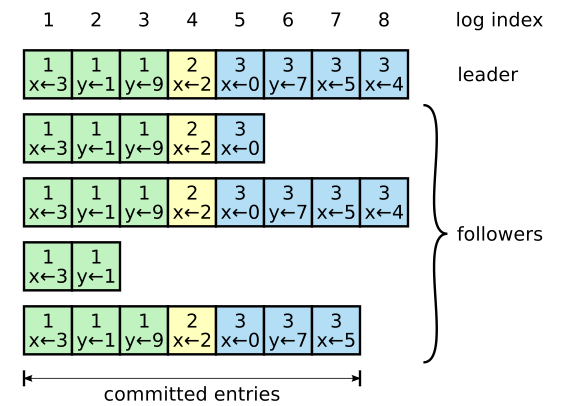
当某个日志记录顺利备份到集群大多数节点上后,Leader 便会认为该日志记录“已提交”(Committed),即该日志记录已可被安全的应用到上层状态机上。Raft 保证一个日志记录一旦被提交,那么它最终就会被所有仍可用的状态机所应用。除外,一条日志记录的提交也意味着位于其之前的所有日志记录也进入“已提交”状态。Leader 会保存其已知的最新的已提交日志的 index 值,并在每次进行 AppendEntries RPC 调用时附带该信息;Follower 在接收到该信息后即可将对应的日志记录应用在位于其上层的状态机上。
在运行时,Raft 能为系统提供如下两点性质,这两点性质共同构成了论文图 3 中提到的 Log Matching 性质:
- 对于两份日志中给定的 index 处,如果该处两个日志记录的 Term ID 相同,那么它们存储的状态机命令相同
- 如果两份日志中给定 index 处的日志记录有相同的 Term ID 值,那么位于它们之前的日志记录完全相同
第一条性质很容易得出,考虑到 Leader 在一个 Term 中只会在一个 index 处创建一条日志记录,而且日志的位置不会发生改变。为了提供上述第二个性质,Leader 在进行 AppendEntries RPC 调用时会同时携带在其自身的日志存储中位于该新日志记录之前的日志记录的 index 值及 Term ID;如果 Follower 在自己的日志存储中没有找到这条日志记录,那么 Follower 就会拒绝这条新记录。由此,每一次 AppendEntries RPC 调用的成功返回都意味着 Leader 可以确定该 Follower 存储的日志直到该 index 处均与自己所存储的日志相同。
AppendEntries RPC 的日志一致性检查是必要的,因为 Leader 的崩溃会导致新 Leader 存储的日志可能和 Follower 不一致。
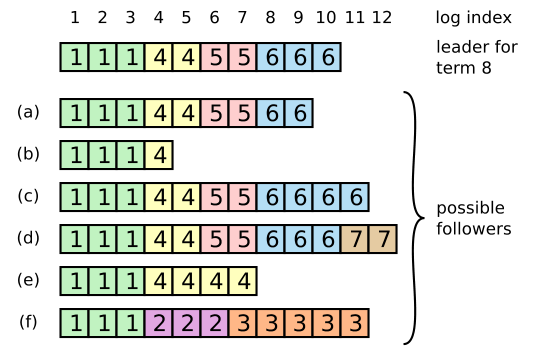
考虑上图(即文中的图 7),对于给定的 Leader 日志,Follower 有可能缺失部分日志(a、b 情形)、有可能包含某些未提交的日志(c、d 情形)、或是两种情况同时发生(e、f 情形)。
对于不一致的 Follower 日志,Raft 会强制要求 Follower 与 Leader 的日志保持一致。为此,Leader 会尝试确定它与各个 Follower 所能相互统一的最后一条日志记录的 index 值,然后就会将 Follower 在该 index 之后的所有日志删除,再将自身存储的日志记录备份到 Follower 上。具体而言:
- Leader 会为每个 Follower 维持一个
nextIndex变量,代表 Leader 即将通过 AppendEntries RPC 调用发往该 Follower 的日志的 index 值 - 在刚刚被选举为一个 Leader 时,Leader 会将每个 Follower 的
nextIndex置为其所保存的最新日志记录的 index 之后 - 当有 Follower 的日志与 Leader 不一致时,Leader 的 AppendEntries RPC 调用会失败,Leader 便对该 Follower 的
nextIndex值减 1 并重试,直到 AppendEntries 成功 - Follower 接收到合法的 AppendEntries 后,便会移除其在该位置上及以后存储的日志记录,并追加上新的日志记录
- 如此,在 AppendEntries 调用成功后,Follower 便会在该 Term 接下来的时间里与 Leader 保持一致
由此,我们实现了前面提及的 Leader Append-Only 和 Log Matching 性质。
Leader 选举约束
就上述所提及的 Leader 选举及日志备份规则,实际上是不足以确保所有状态机都能按照相同的顺序执行相同的命令的。例如,在集群运行的过程中,某个 Follower 可能会失效,而 Leader 继续在集群中提交日志记录;当这个 Follower 恢复后,有可能会被选举为 Leader,而它实际上缺少了一些已经提交的日志记录。
其他的基于 Leader 架构的共识算法都会保证 Leader 最终会持有所有已提交的日志记录。一些算法(如 Viewstamped Replication)允许节点在不持有所有已提交日志记录的情况下被选举为 Leader,并通过其他机制将缺失的日志记录发送至新 Leader。而这种机制实际上会为算法引入额外的复杂度。为了简化算法,Raft 限制了日志记录只会从 Leader 流向 Follower,同时 Leader 绝不会覆写它所保存的日志。
在这样的前提下,要提供相同的保证,Raft 就需要限制哪些 Candidate 可以成为 Leader。前面提到,Candidate 为了成为 Leader 需要获得集群内大多数节点的选票,而一个日志记录被提交同样要求它已经被备份到集群内的大多数节点上,那么如果一个 Candidate 能够成为 Leader,投票给它的节点中必然存在节点保存有所有已提交的日志记录。Candidate 在发送 RequestVote RPC 调用进行拉票时,它还会附带上自己的日志中最后一条记录的 index 值和 Term ID 值:其他节点在接收到后会与自己的日志进行比较,如果发现对方的日志落后于自己的日志(首先由 Term ID 决定大小,在 Term ID 相同时由 index 决定大小),就会拒绝这次 RPC 调用。如此一来,Raft 就能确保被选举为 Leader 的节点必然包含所有已经提交的日志。
来自旧 Term 的日志记录
如上文所述,Leader 在备份当前 Term 的日志记录时,在成功备份至集群大多数节点上后 Leader 即可认为该日志记录已提交。但如果 Leader 在日志记录备份至大多数节点之前就崩溃了,后续的 Leader 会尝试继续备份该日志。然而,此时的 Leader 即使在将该日志备份至大多数节点上后都无法立刻得出该日志已提交的结论。
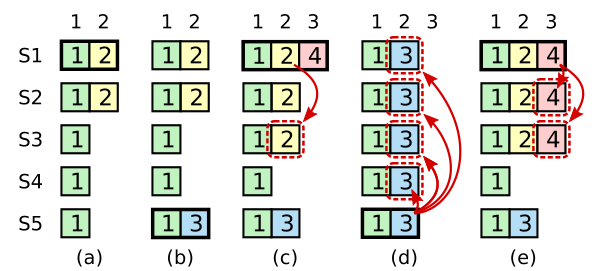
考虑上图这种情形。在时间点 (a) 时,S1 是 Leader,并把 (TermID=2, index=2) 的日志记录备份到了 S2 上。到了时间点 (b) 时,S1 崩溃,S5 收到 S3、S4、S5 的选票,被选为 Leader,并从客户端处接收到日志记录 (TermID=3, index=2)。在时间点 (c) 时,S5 崩溃,S1 重启,被选举为 Leader,并继续将先前没有备份的日志记录 (TermID=2, index=2) 备份到其他节点上。即便此时 S1 顺利把该日志记录备份到集群大多数节点上,它仍然不能认为该日志记录已被安全提交。考虑此时 S1 崩溃,S5 将可以收到来自 S2、S3、S4、S5 的选票,成为 Leader(其最后一个日志记录的 Term ID 是 3,大于 2),进入情形 (d):此时 S5 会继续把日志记录 (TermID=3, index=2) 备份到其他节点上,覆盖掉原本已经备份至大多数节点的日志记录 (TermID=2, index=2)。然而,如果在时间点 (c) S1 成为 Leader 后,同样将当前 Term 的最新日志记录 (TermID=4, index=3) 备份出去并提交,就会进入情形 (e),此时 S5 便无法再被选举为 Leader。因此,解决该问题的关键在于在备份旧 Term 的日志时也要把当前 Term 最新的日志一并分发出去。
由此,Raft 只会在备份当前 Term 的日志记录时才会通过计数的方式来判断该日志记录是否已被提交;一旦该日志记录完成提交,根据前面提及的 Log Matching 性质,Leader 就能得出之前的日志记录也已被提交。由此,我们便实现了前面提及的 Leader Completeness 性质。文中 5.4.3 节有完整的证明过程,感兴趣的读者可自行查阅。
证得前面 4 条性质后,最后一条 State Machine Safety 性质也可证得:当节点将日志记录应用于其上层状态机时,该日志记录及其之前的所有日志记录必然已经提交。某些节点执行命令的进度可能落后,我们考虑所有节点目前已执行日志记录的 index 值的最小值:Log Completeness 性质保证了未来的所有 Leader 都会持有该日志记录,因此在之后的 Term 中其他节点应用位于该 index 处的日志记录时,该日志记录保存的必然是相同的命令。由此,上层状态机只要按照 Raft 日志记录的 index 值顺序执行命令即可安全完成状态备份。
时序要求
为了提供合理的可用性,集群仍需满足一定的时序要求,具体如下:
$$
broadcastTime \ll electionTimeout \ll MTBF
$$
其中 $broadcastTime$ 即一个节点并发地发送 RPC 请求至集群中其他节点并接收请求的平均耗时;$electionTimeout$ 即节点的选举超时时间;$MTBF$ 即单个节点每次失效的平均间隔时间(Mean Time Between Failures)。
上述的不等式要求,$broadcastTime$ 要小于 $electionTimeout$ 一个数量级,以确保正常 Leader 心跳间隔不会导致 Follower 超时并发起选举;同时考虑到 $electionTimeout$ 会随机选出,该不等式还能确保 Leader 选举时平局局面不会频繁出现。除外,$electionTimeout$ 也应比 $MTBF$ 小几个数量级,考虑到系统会在 Leader 失效时停止服务,而这样的情况不应当频繁出现。
在这个不等式中,$broadcastTime$ 及 $MTBF$ 由集群架构所决定,$electionTimeout$ 则可由运维人员自行配置。
Candidate 与 Follower 失效
目前来讲我们讨论都是 Leader 失效的问题。对于 Candidate 和 Follower 而言,它们分别是 RequestVote 和 AppendEntries RPC 调用的接收方:当 Candidate 或 Follower 崩溃后,RPC 调用会失败;Raft RPC 失败时会不断重试 RPC,直至 RPC 成功;除外,RPC 调用也有可能已经生效,但接收方在响应前就已失效,为此 Raft 保证 RPC 的幂等性,在节点重启后收到重复的 RPC 调用也不会有所影响。
集群成员变更
直到目前为止,我们的讨论都假设集群的成员配置是一成不变的,然而这在系统的正常运维中是不常见的:系统总是可能需要做出变更,例如移除一些节点或增加一些节点。
当然,集群可以被全部关闭后,调整配置文件,再全部重启,这样也能完成集群配置变更,但这样会导致系统出现一段时间的不可用。而 Raft 则引入了额外的机制来允许集群在运行中变更自己的成员配置。
在进行配置变更时,直接从旧配置切换至新配置是不可行的,源于不同的节点不可能原子地完成配置切换,而这之间可能会有一些时间间隙使得集群存在两个不同的“大多数”。
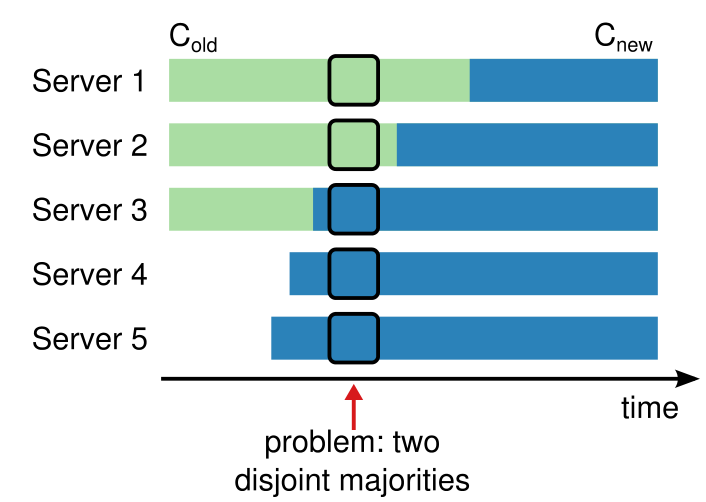
如上图所示,集群逐渐地从旧配置切换至新配置,那么在箭头标记的位置就出现了两个不同的“大多数”:S1、S2 构成 $C_{old}$ 的大多数,S3、S4、S5 构成 $C_{new}$ 的大多数。在这一时间间隔内,处于两个配置的节点可能会选出各自的 Leader,引入 Split-Brain 问题。问题的关键在于,在这段时间间隔中,$C_{old}$ 和 $C_{new}$ 都能够独立地做出决定。
为了解决这个问题,Raft 采用二阶段的方式来完成配置切换:在 $C_{old}$ 与 $C_{new}$ 之间,引入一个被称为 Joint Consensus 的特殊配置 $C_{old,new}$ 作为迁移状态。该配置有如下性质:
- 日志记录会被备份到 $C_{old}$ 及 $C_{new}$ 的节点上
- 两份配置中的任意机器都能成为 Leader
- 选举或提交日志记录要求得到来自 $C_{old}$ 和 $C_{new}$ 的两个不同的“大多数”的同意
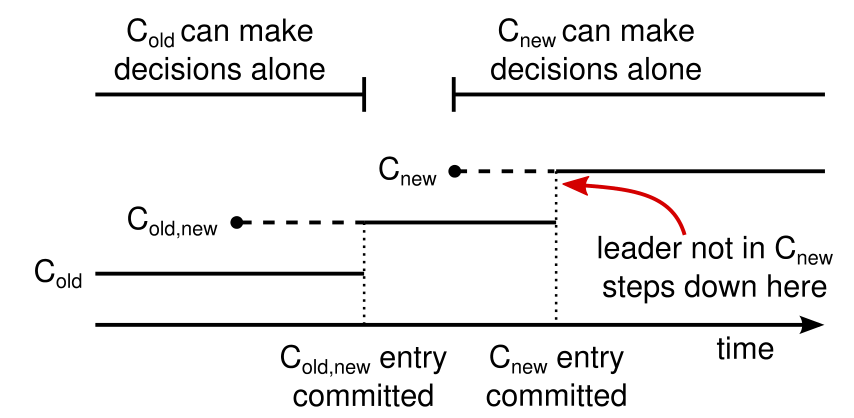
上图显示了配置切换的时序,其中可以看到不存在 $C_{old}$ 和 $C_{new}$ 都能独立作出决定的时间段。
切换时,Leader 会创建特殊的配置切换日志,并利用先前提到的日志备份机制通知其他节点进行配置切换。对于这种特殊的配置切换日志,节点在接收到时就会立刻切换配置,不会等待日志提交,因此 Leader 会首先进入 $C_{old,new}$ 配置,同时运用这份配置来判断配置切换的日志是否成功提交。如此,如果 Leader 在完成提交这份日志之前崩溃,新的 Leader 只会处于 $C_{old}$ 或 $C_{old,new}$ 配置,如此一来在该日志记录完成提交前,$C_{new}$ 便无法独立做出决定。
在 $C_{old,new}$ 的配置变更日志完成提交后,$C_{old}$ 便也不能独立做出决定了,且 Leader Completeness 性质保证了此时选举出的 Leader 必然处于 $C_{old,new}$ 配置。此时,Leader 就能开始重复上述过程,切换到 $C_{new}$ 配置。在 $C_{new}$ 配置日志完成提交后,这个过程中被移出集群的节点就能顺利关闭了。
除此以外,我们仍有三个问题需要去解决。
首先,配置变更可能会引入新的节点,这些节点不包含之前的日志记录,完成日志备份可能会需要较长的时间,而这段时间可能导致集群无法提交日志,引入一段时间的服务不可用。为此,Raft 在节点变更配置之前还引入了一个额外的阶段:此时节点会以不投票成员的形式加入集群,开始备份日志,Leader 在计算“大多数”时也不会考虑它们;等到它们完成备份后,它们就能回到正常状态,完成配置切换。
此外,集群的 Leader 有可能不属于 $C_{new}$。在这种情况下,Leader 在完成 $C_{new}$ 的配置变更日志提交后才能变更自己的配置并关闭。也就是说,在 Leader 提交 $C_{new}$ 的日志时,那段时间里它会需要管理一个不包含自己的集群:它会把日志记录备份出去,但不会把自己算入“大多数”。直到 $C_{new}$ 日志完成提交,$C_{new}$ 才能够独立做出决定,才能够在原 Leader 降级后在 $C_{new}$ 集群中选出新的 Leader;在那之前,来自 $C_{old}$ 的节点有可能被选为 Leader。
最后,那些从集群中被移除出去的节点可能会在配置切换完成后干扰新集群的运行。这些节点不会再接收到 Leader 的心跳,于是它们就会超时并发起选举。这时它们会发起 RequestVote RPC 调用,其中包含新的 Term ID,而这可能导致新的 Leader 自动降级为 Follower,导致服务不可用。最终新集群会选出一个新的 Leader,但被移除的节点依旧不会接收到心跳信息,它们会再次超时,再次发起选举,如此循环往复。
为解决此问题,节点在其“确信” Leader 仍存活时会拒绝 RequestVote RPC 调用:如果距离节点上一次接收到 Leader 心跳信息过去的时间小于 Election Timeout 的最小值,那么节点便会“确信” Leader 仍然存活。考虑前面提到的时序要求,这确实能够在大多数情况下避免该问题。
日志压缩
随着 Raft 集群的不断运行,节点上的日志体积会不断增大,这会逐渐占用节点的磁盘资源,此外过长的日志也会延长节点重放日志的耗时,引入服务可用性问题。为此,集群需要对过往的日志进行压缩。
快照是进行日志压缩最简便的方案。在进行快照时,状态机当前的完整状态会被写入到持久存储中,而后就能够安全地把直到该时间点以前的日志记录移除了。完成快照后,Raft 也会在快照中记录其所覆盖到的最新日志记录的 index 和 Term ID,以便后面的日志记录能够被继续追加。为了兼容前面提到的集群成员配置变更,快照同样需要记录下当前的集群成员配置。
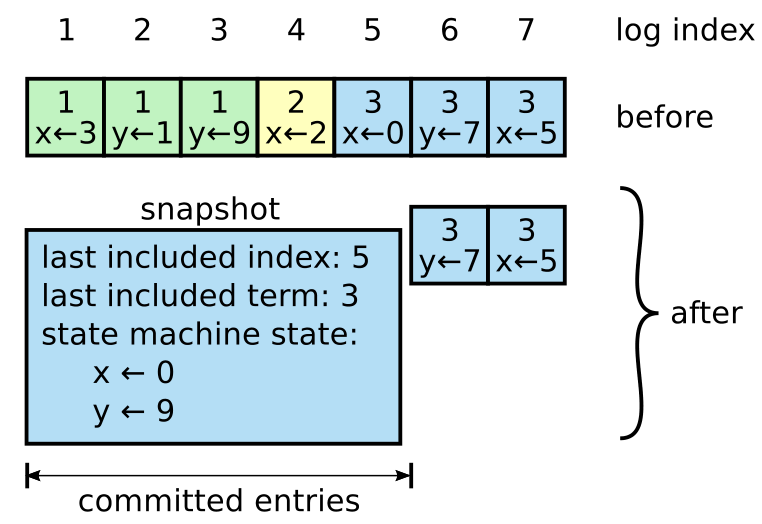
对于 Raft 来说,每个节点会独立地生成快照。相比起只由 Leader 生成快照,这样的设计避免了 Leader 频繁向其他 Follower 传输快照而占用网络带宽,况且 Follower 也持有着足以独立生成快照的数据。
尽管如此,当某个 Follower 落后太多或是集群加入了新节点时,Leader 仍然会需要将自己持有的快照传输给 Follower。为此,Raft 提供了专门的 InstallSnapshot RPC 接口。
InstallSnapshot RPC: 由 Leader 进行调用,用于将组成快照的文件块发给指定 Follower。Leader 总会按照顺序发送文件块。
参数:
term: Leader 当前的 Term IDleaderId: Leader 的 IDlastIncludedIndex: 该快照所覆盖的最后一个日志记录的 index 值lastIncludedTerm: 该快照所覆盖的最后一个日志记录的 Term IDoffset: 当前发送的文件块在整个快照文件中的偏移值data[]: 文件块的内容done: 该文件块是否为最后一个文件块返回值:
term: Follower 的当前 Term ID。Leader 可根据该值判断是否要降级为 Follower。Follower 在接收到该 RPC 调用后会进行以下操作:
- 若
term < currentTerm,return- 若
offset == 0,创建快照文件- 在快照文件的指定
offset处写入data[]- 若
done == false,返回响应,并继续等待其他文件块- 移除已有的或正在生成的在该快照之前的快照
- 如果有一个日志记录的 Term ID 及 index 值与该快照所包含的最后一个日志记录相同,那么便保留该日志记录之后的日志记录,并返回响应
- 移除被该快照覆盖的所有日志记录
- 使用该快照的内容重置上层状态机,并载入快照所携带的集群成员配置
客户端交互
最后,我们再来聊聊客户端如何与 Raft 集群进行交互。
首先,客户端需要能够得知目前 Raft 集群的 Leader 是谁。在一开始,客户端会与集群中任意的一个节点进行通信:如果该节点不是 Leader,那么它会把上一次接收到的 AppendEntries RPC 调用中携带的 Leader ID 返回给客户端;如果客户端无法连接至该节点,那么客户端就会再次随机选取一个节点进行重试。
Raft 的目标之一是为上层状态机提供日志记录的 exactly-once 语义,但如果 Leader 在完成日志提交后、向客户端返回响应之前崩溃,客户端就会重试发送该日志记录。为此,客户端需要为自己的每一次通信赋予独有的序列号,而上层状态机则需要为每个客户端记录其上一次通信所携带的序列号以及对应的响应内容,如此一来当收到重复的调用时状态机便可在不执行该命令的情况下返回响应。
对于客户端的只读请求,Raft 集群可以在不对日志进行任何写入的情况下返回响应。然而,这有可能让客户端读取到过时的数据,源于当前与客户端通信的 “Leader” 可能已经不是集群的实际 Leader,而它自己并不知情。
为了解决此问题,Raft 必须提供两个保证。首先,Leader 持有关于哪个日志记录已经成功提交的最新信息。基于前面提到的 Leader Completeness 性质,节点在成为 Leader 后会立刻添加一个空白的 no-op 日志记录;此外,Leader 还需要知道自己是否已经需要降级,为此 Leader 在处理只读请求前需要先与集群大多数节点完成心跳通信,以确保自己仍是集群的实际 Leader。
结语
至此,本文已对 Raft 论文的内容进行了完整的总结。总体而言,Raft 的论文为 Raft 提供了很详实的介绍,论文各处的 API Specification 也为他人实现 Raft 算法提供了很好的基础。Raft 算法也存在着一些在论文中也没有提及的细节及优化方式,有机会的话我会在新的博文中介绍这部分的内容,敬请期待。

