SparkSQL Hive ThriftServer 源码解析:Intro
本人的第一个实习工作是在一家小公司做研发工作。这家公司以 Spark 平台为基础开发出了一款大数据分析平台作为其核心产品。工作性质使然,我需要掌握 Spark 的运行原理,工作更要求我去阅读和理解 Spark 的源代码。这篇博文只是我的一时心血来潮:一来可以巩固我所学的知识,二来也希望我的理解能够帮到后来的人。
首先,必须承认 Spark 本身是一个十分复杂的系统,Scala 作为 Spark 的主要开发语言,其相较于 Java 差得多的可读性也为源代码阅读带来了相当大的挑战。SparkSQL 作为 Spark 的一个模块,也相当的复杂,我并不认为自己有能力在如此短时间的源代码阅读过程中就能够把 SparkSQL 模块琢磨透。因此这篇文章更像是我开的一个坑:我会慢慢地更新这篇文章,不断地修正我对 SparkSQL 本身的理解。同时也希望读者不要过于相信我的一家之言,因为我很有可能是错的。如果您在某些问题上有比我更好的见解,随时欢迎您用电子邮件与我联系进行深入交流。
本文中所出现的源代码皆为写作时最新的 Spark 1.4.1 中的源代码。
SparkSQL 模块综述
Spark 的主要开发语言是 Scala,同时包含部分 Java 代码。以模块为单位的话,不去管其他模块,在 Spark 1.4.1 中的 SparkSQL 模块全部由 Scala 编写而成,因此本文要求读者拥有阅读 Scala 源代码的能力。对于并未学习过 Scala 语言的读者,我由衷地建议您在学习过 Scala 后再在此文的指导下阅读 SparkSQL 的源代码。
在利用 IntelliJ 构建完 Spark 源码阅读环境后,打开项目的 sql 文件夹,就会看到有四个文件夹:catalyst 、 core 、 hive 、 hive-thriftserver。这四个文件夹分别属于 SparkSQL 的四个项目:spark-catalyst_2.10 、 spark-sql_2.10 、 spark-hive_2.10 、 spark-hive-thriftserver_2.10。初来乍到很容易被这四个文件夹吓晕,因为这四个文件夹下面各自都是一个 Maven 项目,而光从项目名称上很难看出每个项目到底有什么用途。但不用担心,Apache Spark 长期以来一直都在 Github 上开源,因此 sql 文件夹以及这四个文件夹下都有 README.md 文件对项目进行详细说明。
我们首先看一下 sql/README.md。其中有这么一段话:
1 | This module provides support for executing relational queries expressed in either SQL or a LINQ-like Scala DSL. |
(如果你不喜欢这个样式,还可以在这里看到由 Github 渲染过的 Readme 说明)
对于有一定英文基础的人来讲,上述说明并不难理解,但在这里我会再详细解释一下,可能会有点啰嗦。
熟悉 SparkSQL 的人都知道,SparkSQL 接受用户输入的 SQL 语句,并将其解析为对应的 Spark 操作,执行计算后返回结果。SparkSQL 的存在让大量的 DBA 找到存在感,同时也大大加快了各大企业开发 Spark 应用的速度,原因在于用 Java、Python、Scala 或 R 写出来的 Spark 应用脚本的专用性过强,业务逻辑中的每个运算都需要程序员明确写明步骤,而且这样的运算脚本复用性极差,基本上完全无法复用。这样的脚本也被部分开发者称为“一次性的 Spark 脚本”。毋庸置疑,开发这样的脚本,效率是极低的。SparkSQL 模块接收程序员输入的 SQL 语句并自动转化为对应的 Spark 运算。突然之间,程序员们从维护一次性脚本变成了维护 SQL 语句,而这正是 DBA 们的专业领域。维护成本大大降低,开发速度大大提高,加之大部分企业以关系型数据库组织自己的业务数据,SparkSQL 可以说为企业的传统数据业务提供了无缝转接。以笔者所在公司为例,该公司核心产品的大部分业务逻辑都是通过 JDBC 发送 SQL 语句至 SparkSQL 模块完成查询的。
说回 SparkSQL 的模块划分。首先最引人注目的,应该是 Hive Support 和 HiveServer 项目。众所周知,Apache Hive 的功能在于将数据文件以表的形式存储在 HDFS 之上。原本的 Hive 与 Hadoop 紧密结合,Hive 通过 JDBC 接收 SQL 语句并将 SQL 解析为 Hadoop 的 MapReduce 操作,处理完毕后返回结果。Spark 本身也可以使用 Hadoop HDFS 存储数据文件,所以 SparkSQL 对 Hive 做出兼容似乎也是合情合理,只是这次 Hive 不再将 SQL 语句变成 MapReduce 操作,而是变成 Spark 操作。其中,hive-thriftserver 项目除了实现了一个 HiveServer2(负责 JDBC/ODBC 连接)还实现了 CLI support 功能,也就是 bin/spark-sql 这个 SQL Shell。而 hive 这个项目,不妨理解为 hive-core,它实现了 SparkSQL 与 Hive 之间的桥梁:HiveContext。它继承自 SQLContext,而且并未改写其中最核心的 sql 方法。
Catalyst,“催化剂”,即 SQL 解析器。它接收 SQL 语句,将其解析为抽象语法树并进一步解析为对应的 Spark 操作树,供执行模块执行。执行模块 Execution,或称 sql core,负责管理和调度接收到的每个查询,同时也是这些查询的执行引擎。在 Catalyst 为每个查询生成了对应的查询计划以后,Execution 便将执行对应操作,将这些查询计划变成结果 RDD(DataFrame)。SparkSQL 核心类 SQLContext 正是位于这个项目之中。
以上便是 SparkSQL 四个模块的介绍。接下来我们先从 Hive ThriftServer 开始。
Start ThriftServer
正如上文所述,Spark ThriftServer 项目负责接受 JDBC 连接,将 JDBC 客户端发来的 SQL 语句转发至 SparkSQL,并在 SparkSQL 计算完毕后将结果 DataFrame 以 ResultSet 的形式返回给客户端。ThriftServer 本身基于 Apache Hive 项目进行开发,大量使用了 Hive 本身的代码,仅在转发至 Hadoop MapReduce 的部分通过继承的方式,改而将 SQL 语句转发至 SparkSQL。因此,我们不难将整个 ThriftServer 分成两个模块进行理解:
- 首先是 Hive Server 模块,角色比较类似于 Tomcat 这样的 Servlet Container。Hive Server 负责监听套接字(
0.0.0.0:10000)、在接收到客户端请求后维护与客户端的连接、接收客户端的请求转发至执行模块并将执行模块的结果(可能已经是ResultSet,也可能仍然是DataFrame)以ResultSet的形式返回。 - 然后是 Hive Service 模块,角色类似于 Servlet。它包含真正的业务逻辑或对真正的业务逻辑的直接调用。它正是上文提到的
thriftserver的执行模块,它调用 SparkSQL 的接口(极有可能就是SQLContext.sql方法)并将结果返回给 Server 模块。
当然,上述只是对 ThriftServer 模块划分及分工的大概猜测,也有可能并不准确,加之如数据表缓存等与上下文(context)有关的功能也暂时无法确定具体是哪个模块负责。But, after all, talk is cheap, show me the code.
首先,我们从 ThriftServer 的启动入口开始。在 Spark 的 sbin 文件夹下有一个名为 start-thriftserver.sh 的脚本文件,通过执行该脚本便可启动 Thrift Server。我们不妨先看看它的内容:
1 | # Usage 打印以及注释等无关语句已被删去 |
可见,该脚本利用 spark-daemon.sh,在后台调用了 spark-submit 接口,执行了 org.apache.spark.sql.hive.thriftserver.HiveThriftServer2。
入口确定,于是我们去找 HiveThriftServer2 的 main 函数吧!
1 | /** |
可见,main 函数创建了一个 HiveThriftServer2 实例,传入 HiveContext 与 HiveConf 实例对其进行初始化并启动。于是我们来看看 HiveThriftServer2:
1 | /** |
我们可以拿上述代码对比一下 HiveServer2 原本的代码:
1 | public class HiveServer2 extends CompositeService { |
仔细看就会发现,这两个方法仅在处理启动参数和 cliService 变量的设置上有所差别。在 Spark ThriftServer 中,cliService 从原本的 org.apache.hive.service.cli.CLIService 变成了 org.apache.spark.sql.hive.thriftserver。同时 HiveThriftServer2 启动了另一个名为 thriftCLISerivce 的服务,这一点上与原本的 HiveServer2 保持一致。这恰恰证明了我们先前的猜想,这个 thriftCLIService 就代表着 Hive Server 模块,cliService 则代表着 Servlet 模块。
除此之外,为了能够顺利的复用 Hive 的功能,Thrift Server 大量的使用了反射机制。HiveThriftServer2 除了继承自 HiveServer2,还混入了 ReflectedCompositeService 特质,而 HiveServer2 继承自 CompositeService 特质。我们可以看一下 ReflectedCompositeService 特质:
1 | /** Reflected,反射 */ |
可以对比一下 CompositleService 的源代码
1 | public class CompositeService extends AbstractService { |
可以看到,CompositeService 维护着一个由 Service 组成的 ArrayList(Composite 意为“复合的”、“混合的”),调用 CompositeService 的 addService 和 removeService 可以向其中添加和删除 Service,而调用 init 和 start 则可以分别调用其中所有 Service 的 init 和 start 方法。稍微对比 ReflectedCompositeService 的代码和 CompositeService 的代码即可得出结论,HiveThriftServer2 中的 initCompositeService(hiveConf) 和 HiveServer2 中的 super.init(hiveConf) 是等价的。
ReflectedCompositeService 是一处。细心的读者还会注意到在 HiveThriftServer2 中还出现了 setSuperField 方法。setSuperField 方法是来自于 org.apache.spark.sql.hive.thriftserver.RefectionUtils 的静态方法。该工具类包含的所有反射工具方法如下:
setSuperField(obj : Object, fieldName: String, fieldValue: Object):将 obj 的直接父类的指定变量置为指定值setAncestorField(obj: AnyRef, level: Int, fieldName: String, fieldValue: AnyRef):将 obj 上 level 级的父类的指定变量置为指定值getSuperField[T](obj: AnyRef, fieldName: String): T:获取 obj 的直接父类的指定变量getAncestorField[T](obj: Object, level: Int, fieldName: String): T:获取 obj 上 level 级的父类的指定变量invokeStatic(clazz: Class[_], methodName: String, args: (Class[_], AnyRef)*): AnyRef:调用某个类的静态函数invoke(clazz: Class[_], obj: AnyRef, methodName: String, args: (Class[_], AnyRef)*): AnyRef:调用某个对象的指定函数
为了能够顺利复用 HiveServer2 的其他方法,HiveThriftServer2 必须设置其父类的 cliService 变量和 thriftCLIService 变量,无奈这两个变量都是 private 的,所以这里才使用了反射机制对其进行设置。包括 ReflectedCompositeService 以及 ReflectionUtils 前 4 个变量相关的方法,希望各位读者能铭记于心。这几个工具方法在整个 Thrift Server 项目中被多次用到。
在 HiveThriftServer2 的 init 方法执行完毕后,Thrift Server 初始化完毕。main 函数接下来便调用了它的 start 方法。start 方法调用其所有通过 addService 注册的服务的 start 方法,服务器正式启动。
总结
感谢您能细心读完本文。如果没有意外的话,您应该已对 SparkSQL ThriftServer 的启动流程有了大致的了解。该流程可用如此表示:
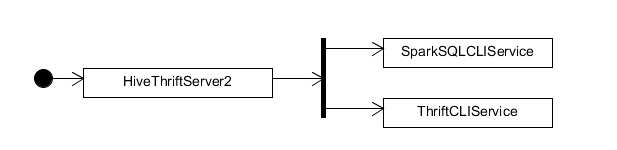
同时,您也了解到,ThriftCliService 充当着 Servlet Container 的角色,维护着与客户端的连接,接收客户端的请求、为客户端发送结果,但主要的业务逻辑并不在里面,而是在充当 Servlet 角色的执行模块 SparkSQLCLIService 内。
在接下来的文章中,我将分两个方向,分别讲解这两个模块的工作原理。敬请期待。
SparkSQL Hive ThriftServer 源码解析:Intro
https://mr-dai.github.io/sparksql_hive_thriftserver_source_1/

