Spinnaker —— 使用 Paxos 构建分布式 KV 数据库
在 MIT 6.824 的 Lecture 7 中,我们将阅读《Using Paxos to Build a Scalable, Consistent, and Highly Available Datastore》一文,看看 LinkedIn 的工程师是如何利用 Paxos 和 ZooKeeper 构建一个名为 Spinnaker 的 KV 数据库的。
这篇文章并不难,有好好理解上一课中关于 Raft 的内容的话就不会有太多的问题。诚如论文标题所属,这次的 Case Study 更多只是学习我们可以怎样利用 Raft/Paxos 来构建一个强一致性的分布式数据库,同时确保它的性能可以进行水平扩展。
点击这里可以阅读我之前的几篇 MIT 6.824 系列文章:
- Lecture 1:MapReduce
- Lecture 3:Google File System
- Lecture 4:Primary-Backup Replication
- Lecture 5 & 6:Raft
背景
对于现在的数据库而言,上层的网络应用开始对其提出越来越高的可扩展性的要求,其中一个比较合理的解决方案便是 Sharding。在以前,Sharding 通常由系统管理员手动完成,并维护数据分片的负载均衡,不过较新型的数据库也已开始支持基于 Key 的 Hash 或 Range 的自动数据分片及负载均衡。
除了性能可扩展以外,应用对于数据库可用性的要求也不低,为此数据库系统也需要提供一定的备份机制,以便在节点失效时仍能对外提供服务。一种比较常见的做法是使用一对相同的节点,以 Master-Slave 的形式进行同步数据备份,但这样的两路备份的解决方案仍然存在着问题(见论文 1.1 节)。
新型的数据库系统开始采用三路备份的结局方案来避免 Master-Slave 架构的问题,但也让节点间的备份协议变得更加复杂。Paxos 一直以来都被看做是这种场景下的唯一选择,但从未被用于进行数据库的备份,因为那会相对更加复杂一些,且较大的数据量也会使得备份速度更低。
由 LinkedIn 开发的 Spinnaker 是一款实验性质的 KV 数据库系统,采用类似 Paxos 的日志备份协议实现了三路数据备份,可基于 Key 的值域对数据进行分片,对外提供事务型的 Get/Put API。除外,Spinnaker 还允许应用程序在使用 Get API 时指定一致性模式,可选择强一致性或是时间轴一致性:使用时间轴一致性时,客户端可能会读取到过时的数据,但相对的也会换来更好的性能。
Why Spinnaker?
MIT 6.824 安排在 Raft 之后学习 Spinnaker 主要有以下几点原因:
- 通过 Spinnaker 学习如何可以使用 Paxos 来构建一个 KV 数据库。在 MIT 6.824 的 Lab 3 中我们就会做一样的事情,只是会用 Raft 而不是 Paxos
- Spinnaker 是少数几个首先尝试使用 Paxos 来实现数据备份的产品,而不只是像 Chubby/ZooKeeper 那样做配置管理
Spinnaker 集群架构
首先,Spinnaker 作为 KV 数据库系统,会把数据按照它们的 Key 进行基于值域的分片,每个分片独立进行备份,常规的 Spinnaker 部署配置通常会把数据分片备份 3 片以上。尽管可以设定更高的备份因子,后续讨论将假设只配置为备份 3 份。
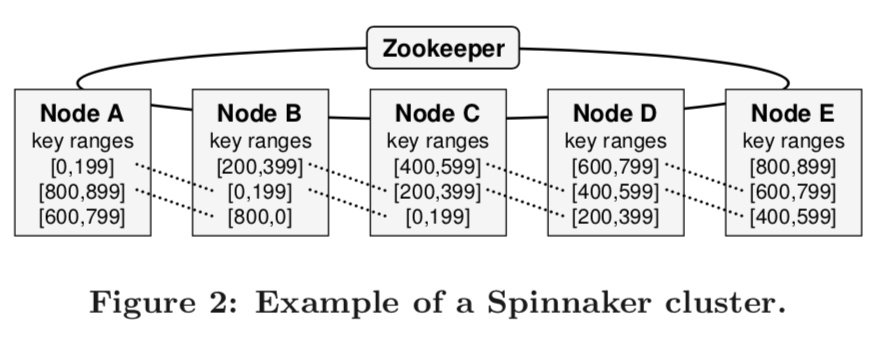
每个数据分片都会有与其相关联的值域(如 $[0, 199]$),持有该数据分片的备份的节点共同组成一个 Cohort(备份组):例如,上图中,节点 A、B、C 就共同组成了分片 $[0, 199]$ 的 Cohort。
每个 Cohort 都会有自己的 Leader,其他成员则作为 Follower。在存储数据时,Leader 首先会以先写日志的形式记录此次数据修改操作,并由 Paxos 对这部分日志备份至 Cohort 的其他成员。已完成提交的操作记录则会采用类似 Bigtable 的形式进行数据写入:数据首先会被写入到 Memtable,待 Memtable 的大小达到一定阈值后再被写出到 SSTable 中。
除外,Spinnaker 还使用了 ZooKeeper 来进行集群协调。ZooKeeper 为 Spinnaker 提供了存储元数据和检测节点失效的有效解决方案,也极大地简化了 Spinnaker 的设计。
Spinnaker 日志备份协议
如上一节所属,在 Spinnaker 运行时,每一组 Cohort 都会有自己独立的 Leader,其他 Cohort 成员作为 Follower,客户端的写操作请求会被路由到 Cohort 的 Leader,由 Leader 与其他 Follower 完成日志备份共识后再写入数据变动并响应客户端。
数据写入
在稳定状态下,Spinnaker 的一次数据写入的步骤如下:
- Spinnaker 将客户端发来的写入请求 $W$ 路由到受影响数据分片对应 Cohort 的 Leader 处
- Leader 为写入请求 $W$ 生成对应的日志记录并追加到其日志中,而后并发地启动两个操作:
- 将写入请求 $W$ 的日志记录刷入到磁盘中
- 将该日志记录放入自己的提交队列,并开始向 Follower 进行备份
- Follower 接收到 Leader 发来的日志后,也会将其刷入磁盘、放入自己的提交队列,然后响应 Leader
- Leader 收到大多数 Follower 的响应后,就会将写入请求 $W$ 应用到自己的 Memtable 上,并响应客户端
除外,Leader 也会周期地与 Follower 进行通信,告知 Follower 当前已提交的操作的序列号,Follower 便可得知先前的日志记录已完成提交,便可将其写入到自己的 Memtable 中。该通信周期被称为 Commit Period(提交周期)。
当客户端发起数据读取请求时,如果启用了强一致性模式,那么请求会被路由到 Leader 上完成,否则就可能会被路由到 Follower 上:正是由于 Commit Period 的存在,被路由到 Follower 上的时间轴一致请求有可能会读取到落后的数据,而落后的程序取决于 Commit Period 的长度。
Follower 恢复
Follwer 的恢复过程可以被分为两个阶段:Local Recovery(本地恢复)和 Catch Up(追数据)。
假设 Follower 已知已提交的最后一条日志记录的序列号为 $f.cmt$。在 Local Recovery 阶段,Follwer 会先应用其本地存储的已知已提交的日志记录到 $f.cmt$,为其 Memtable 进行恢复。如果 Follower 的磁盘失效、所有数据都已丢失,那么 Follower 直接进入 Catch Up 阶段。
在 Catch Up 阶段,Follower 会向 Leader 告知其 $f.cmt$ 的值,Leader 便会向 Follower 发送 $f.cmt$ 后已完成提交的日志记录。
Leader 选举
如上文所述,Spinnaker 主要借助 ZooKeeper 来侦测节点的失效事件。在一个 Cohort 的 Leader 失效时,其他 Follower 就会尝试成为 Leader。借助 ZooKeeper,Spinnaker 的 Leader 选举机制十分简单,只要确保新的 Leader 持有旧 Leader 所有已提交的日志记录即可。
这里我们先假设几个变量,以辅助后续的讨论:
- 令 $l.cmt$ 为 Leader 最后提交的日志的序列号
- 令 $l.lst$ 为 Leader 保存的最后一条日志的序列号
- 令 $f.cmt$ 为 Follwer $f$ 已知已提交的最后一条日志的序列号
- 令 $f.lst$ 为 Follwer $f$ 持有的最后一条日志的序列号
Spinnaker 的每个节点都会连接到 ZooKeeper 以进行 Leader 选举。假设目前正在进行 Leader 选举的 Cohort 对应的 Key 值域为 $r$,那么进行 Leader 选举所需的所有信息都会被保存到 ZooKeeper 的 /r 目录下。Leader 选举的过程如下:
- 其中一个节点删除
/r目录下的旧数据,代表发起 Leader 选举 - 每个 Follower 节点将自己的 $f.lst$ 写入到 ZooKeeper Ephemeral Znode
/r/candidates之中 - 等待大多数节点完成上述步骤
- $f.lst$ 值最大的 Follower 节点成为新的 Leader,并将自己的 Hostname 写入到
/r/leader中 - 其他 Follower 通过读取
/r/leader获知新 Leader 的身份
在选举出新 Leader 后,新 Leader 会进行以下操作:
- 为每个 Follwer,发送 $(f.cmt, l.cmt]$ 之间的日志,再发送 $l.cmt$ 日志已提交的信息
- 待有至少一个 Follwer 追上 $l.cmt$ 后,便开始按照常规的备份协议完成 $(l.cmt, l.lst]$ 的日志提交
日志压缩与合并
在实现 Spinnaker 时的一个比较主要的 Engineering Chanllenge 在于如何避免因为过多的磁盘 IO 导致系统的性能底下。
从上文中所描述的 Spinnaker 集群架构可知,每个节点会持有不止一个数据分片,也就是说节点会同时属于多个 Cohort,但每个 Cohort 会独立地进行日志备份和写入。如果每个 Cohort 的日志都写入到独立的文件中,必然会引入大量的磁盘寻址消耗,所以 Spinnaker 会把同一个节点不同 Cohort 的日志写入到同一个文件中,在节点恢复时也可以在一次文件扫描中就完成所有 Cohort 的恢复,只需要在日志层面上区分其所属 Cohort 即可。
尽管如此,由于从 Follower 写入日志到日志实际提交中存在时间差,Follower 恢复时可能会观察到部分已写入磁盘的日志最终并未完成提交,需要将其从日志存储中移除,但考虑到不同 Cohort 的日志都存储在同一个文件中,这样的操作开销很大。为此,Spinnaker 引入了日志的 Logical Truncation(逻辑截断)机制:处于 Cohort 日志列表尾部需要移除的日志记录会被记录到一个 Skipped LSN 列表中,并写入到磁盘内,这样后续进行 Local Recovery 时,Follower 就会知道需要跳过这部分日志。
除外,使用固态硬盘也能很大程度上避免上述问题。如上文所述,不能在物理上区分不同 Cohort 日志的存储路径的原因在于机械磁盘的磁头寻址时间,而固态硬盘不存在这样的问题,因此在使用固态硬盘时,上述复杂的日志机制就变得没有意义了。在论文的附录 D.4 中讨论了使用固态硬盘的场景及相关的性能基准测试结果,可见使用固态硬盘时 Spinnaker 的写入性能有了 10 倍以上的提升。
结语
如前文所述,这次 Spinnaker 的 Case Study 很好地讲述了如何可以利用 Raft/Paxos 来实现一个一致、高可用且可扩展的数据库系统。尽管 Spinnaker 很大程度上利用了 ZooKeeper 来简化自身的设计,但这部分内容也是可以通过 Raft/Paxos 这种分布式共识协议来实现的。
在完成本文的阅读后,我们实际上就可以开始 MIT 6.824 Lab 3 的实践了。后续我会以专门的系列文章来介绍 MIT 6.824 的 Lab 内容,敬请期待。
Spinnaker —— 使用 Paxos 构建分布式 KV 数据库

