ZooKeeper —— 分布式系统协调服务
来到 MIT 6.824 的 Lecture 8,我们终于要开始读大名鼎鼎的 ZooKeeper 的论文了。Introducing… 《ZooKeeper: Wait-free Coordination for Internet-scale Systems》.
在 Lecture 7 中,我们通过阅读 Spinnaker 的论文了解了如何使用 Paxos 来构建一个数据存储,其论文提到 Spinnaker 使用了 ZooKeeper 来进行集群协调以简化自身的实现,那这次我们就可以来了解一下 ZooKeeper 都提供了哪些功能了。
点击这里可以阅读我之前的几篇 MIT 6.824 系列文章:
- Lecture 1:MapReduce
- Lecture 3:Google File System
- Lecture 4:Primary-Backup Replication
- Lecture 5 & 6:Raft
- Lecture 7:Spinnaker
Zab
ZooKeeper 本身的难点并不多,因此在开始介绍 ZooKeeper 之前,我们不妨先来了解下 ZooKeeper 所用到的共识算法,Zab。
Zab,即 ZooKeeper Atomic Broadcast,在定位上和 Raft 比较接近,但考虑到其是 ZooKeeper 专用的公式算法,功能上相对而言会更加轻量一些。实际上,Zab 也仅仅是把自己定位为“原子广播协议”,而不是 Raft 的“分布式共识算法”。在学习过 Raft 以后,想必 Zab 提供的功能对大家而言应该不会太陌生,因此这里只对 Zab 进行简单的介绍,详情可参考论文《A Simple Totally Ordered Broadcast Protocol》。
和 Raft 类似,Zab 集群由一个 Leader 节点和若干个 Follower 节点构成,整个系统的运行同样需要大多数的 Follower 节点在线。
当需要对数据存储进行变更时,整个流程基本可以视为一个简单的 2PC 流程:
- Propose:Leader 向其他所有节点广播即将进行的操作;接收到的节点将该操作写入先写日志
- Leader 等待,直到接收到大多数节点返回的 ACK
- Commit:Leader 对自己保存的数据存储备份进行变更,并通知其他节点完成相同的操作
作为一个原子广播协议,Zab 提供以下可靠性和消息顺序保证:
- Reliable Delivery(可靠消息投递):如果消息 $m$ 被投递到了一个节点上,那么它最终也会被投递到其他所有节点上(注:原文使用了 Delivery 一词,有消息投递的意思,但结合上下文来看更多指节点接收到消息并写入到先写日志的过程。这里暂译作“投递”)
- Total Order(全序):如果消息 $a$ 在消息 $b$ 之前被投递到一个节点上,那么所有投递了 $a$ 和 $b$ 的节点都会先投递 $a$ 再投递 $b$
- Causal Order(因果序):如果消息 $a$ Causally Precede(因果地领先于)消息 $b$,那么 $a$ 必须排在 $b$ 之前
对于上述第三项功能的 Causally Precede,文中也给出了详细解释,具体包含两种情况:
- 如果消息 $a$ 和 $b$ 发自同一个节点,且 $a$ 在 $b$ 之前 Propose,那么 $a$ Causally Precede $b$
- 如果发生了 Leader 切换,那么上一任 Leader Propose 的消息全部 Causally Precede 新 Leader Propose 的消息
在 Leader 失效进行切换时,Zab 也会进入恢复模式,等待出现新的 Leader 并完成与大多数 Follower 节点的同步。大致上与 Raft 相同,可惜的是论文中没有详细说明 Zab 的 Leader 选举流程。
ZooKeeper
在了解过 Zab 以后,我们再来看看 ZooKeeper。
按照论文的描述,Apache ZooKeeper 的定位是 Coordination Kernel,即通过提供一些基本的原语 API 来辅助上层分布式应用实现进程间的协调。从功能上看,ZooKeeper 提供了一个基于目录树结构的内存型 KV 存储:数据统一以 ZNode 的形式保存在各个 ZooKeeper 节点的内存中,数据的变更由 Leader 节点通过 Zab 协议同步给所有的 Follower 节点。
要使用 ZooKeeper 服务时,客户端只需要与 ZooKeeper 集群的任一节点建立连接即可,客户端的所有读写请求都会由该节点来负责处理。如果是读请求,节点将会使用自身保存的数据直接返回结果;写请求则会被转发给 Leader 节点进行处理。
比起仅提供同步写入的接口,ZooKeeper 也提供了异步写入的接口:客户端可以同时发起多个写请求,无须顺序等待其结果返回。这样的 API 使得客户端可以以更高的吞吐量完成数据变更,而对于来自同一个客户端的并发请求,ZooKeeper 也提供了 FIFO 的顺序保证。
除外,ZooKeeper 还支持 Watch 功能。客户端在对 ZNode 发起读请求时,可以通过额外的参数设定监听该 ZNode 未来的变更事件。当后续该 ZNode 中保存的内容发生了变化后,与客户端连接的 ZooKeeper 节点就会为客户端发来通知消息。
写操作流程
这里我们来详细说说 ZooKeeper 处理一次写操作的具体流程。大体来看,ZooKeeper 对一次写操作的处理可以分为以下几步:
- Leader 对写操作进行预处理,转换为等价 ZooKeeper 事务
- Leader 通过 Zab 协议向所有 Follower 节点 Propose 该事务
- Leader 收到大多数 Follower 节点的 ACK 信息,对事务进行 Commit,应用变更到数据存储
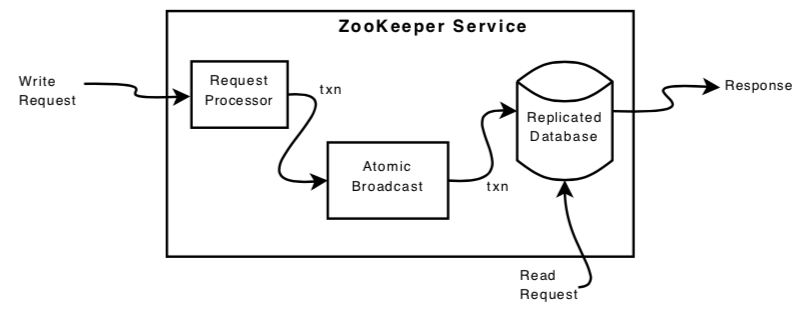
在预处理阶段,Leader 首先会将客户端发来的写请求转换为等价的幂等 ZooKeeper 事务。每个事务都明确的表明了其执行前的期望状态和执行完成后的结果状态。考虑到 Leader 永远持有最新的数据,Leader 是最适合使用自身保存的数据来计算对应的 ZooKeeper 事务的。
这里 ZooKeeper 事务的幂等性还为 Zab 的实现带来的便利,使得 Zab 无论是在正常的数据传递还是节点恢复时都不需要保证消息传递的 exactly-once 语义,只需要保证消息传递的顺序以及 at-least-once 投递即可。
ZooKeeper 还会为每一个 ZooKeeper 事务赋予名为 ZXID 的 64 位唯一 ID 进行标识,其中低 32 位为该事务在此次任期中的序列号,高 32 位为当前 Leader 所属任期的 epoch 值,用于区分不同 Leader 发来的消息。
ZXID 中保存的信息和 Raft 的日志 ID 基本相同,差别在于 Raft 使用了两个 int64 位来保存这两个信息,而 ZooKeeper 则等价于使用了两个 int32 位来进行保存,位数上的差距使得 ZooKeeper 对应字段所能存储的值域明显地受限。在实际使用的过程中,ZooKeeper 也会发生因低 32 位空间被耗尽而导致 ZooKeeper 必须主动进行 Leader 切换的问题。
在完成 ZooKeeper 事务转换后,Leader 便会使用 Zab 协议完成该事务的广播,并最终将数据变更写入到数据存储。
快照与数据恢复
为了应对节点失效的情景,ZooKeeper 也会对所保存的数据周期地保存到磁盘中,生成快照,以在节点失效重启后能够快速地从最近的快照中恢复数据状态。
ZooKeeper 在生成数据快照的过程中不需要锁死整个服务,快照生成与客户端请求处理会并发进行。这就导致了,最终 ZooKeeper 生成的数据快照可能不会对应 ZooKeeper 在任意一个时间点上的实际状态。
要进行数据恢复也很简单:考虑到 ZooKeeper 事务幂等的特性,快照只需要一并记录其开始生成时对应的 TXID,恢复时直接从该事务开始恢复即可。
结语
类似于 Spinnaker,此次 ZooKeeper 也是使用 Paxos/Raft 库构建分布式备份服务的一次很好的 Case Study,主要在于两点:
- 作为“协调内核”服务,ZooKeeper 对外提供的 API 设计及顺序和一致性保证
- ZooKeeper 针对大型分布式应用场景所做出的性能优化设计
在定位上,ZooKeeper 和 etcd 也比较相似,本质上都是基于主从备份的强一致性 KV 数据存储,但在 API 设计上还是存在一定的差异,底层设计上则更是千差万别。感兴趣的同学也建议同样去了解一下 etcd 的设计,以综合对比不同的分布式系统协调服务。
ZooKeeper 的论文中也描述了很多如何利用 ZooKeeper 提供的基本 API 实现某些常见的分布式系统协调模式,感兴趣的同学也可自行阅读论文的第 3 章。
ZooKeeper —— 分布式系统协调服务

