分布式一致性模型介绍
在阅读不同的分布式系统论文时发现,论文中经常会提到该系统实现了一个什么样的一致性模型。了解常见的几种一致性模型的定义想必会对后续的论文阅读有不少的帮助。
这篇文章的内容梳理自此前我在公司内部做的技术分享,介绍了分布式系统的一致性模型是什么,有哪些常见的一致性模型,以及常见的分布式一致性实现方式。
因为是整理自我以前做过的分享,本文会有大量的 PPT 截图,此外也会有一些当时我向听众的提问,也会以思考题的形式梳理在本文中,题目的答案可以在文末找到。
一致性与一致性模型
在这一节中,我们先来看一下分布式系统的一致性和一致性模型的定义。
众所周知,一个分布式系统为了保证数据服务的可靠性,一种常用的实现方式就是 数据备份:

在数据备份模式中,分布式系统会在不同的节点上存储相同的数据,这样当部分节点失效时,其他节点上也能有完整的数据来响应外部的请求,从而保证服务的高可用。
数据备份模式并不局限于常见的分布式数据库系统。如 DNS、CDN,甚至是客户端的 HTTP 请求缓存,都可以被视为数据备份的一种形式,因为本质上它们都是在不同的机器节点上存储了相同的数据。
而分布式系统的所谓 一致性,即指每份数据备份的内容相同。
CAP 理论中的一致性,指 外部的每个读操作都能返回最新的写入结果,即系统能够对外呈现一致的数据视图即可,不要求内部每个节点时刻都持有相同的数据。

在介绍一致性模型的定义之前,我们先来看一种最简单也是最理想的一致性模型:严格一致性(Strict Consistency)。
严格一致性模型要求,在分布式系统一个节点上的数据写入 立刻 就对其他 所有 节点可见:
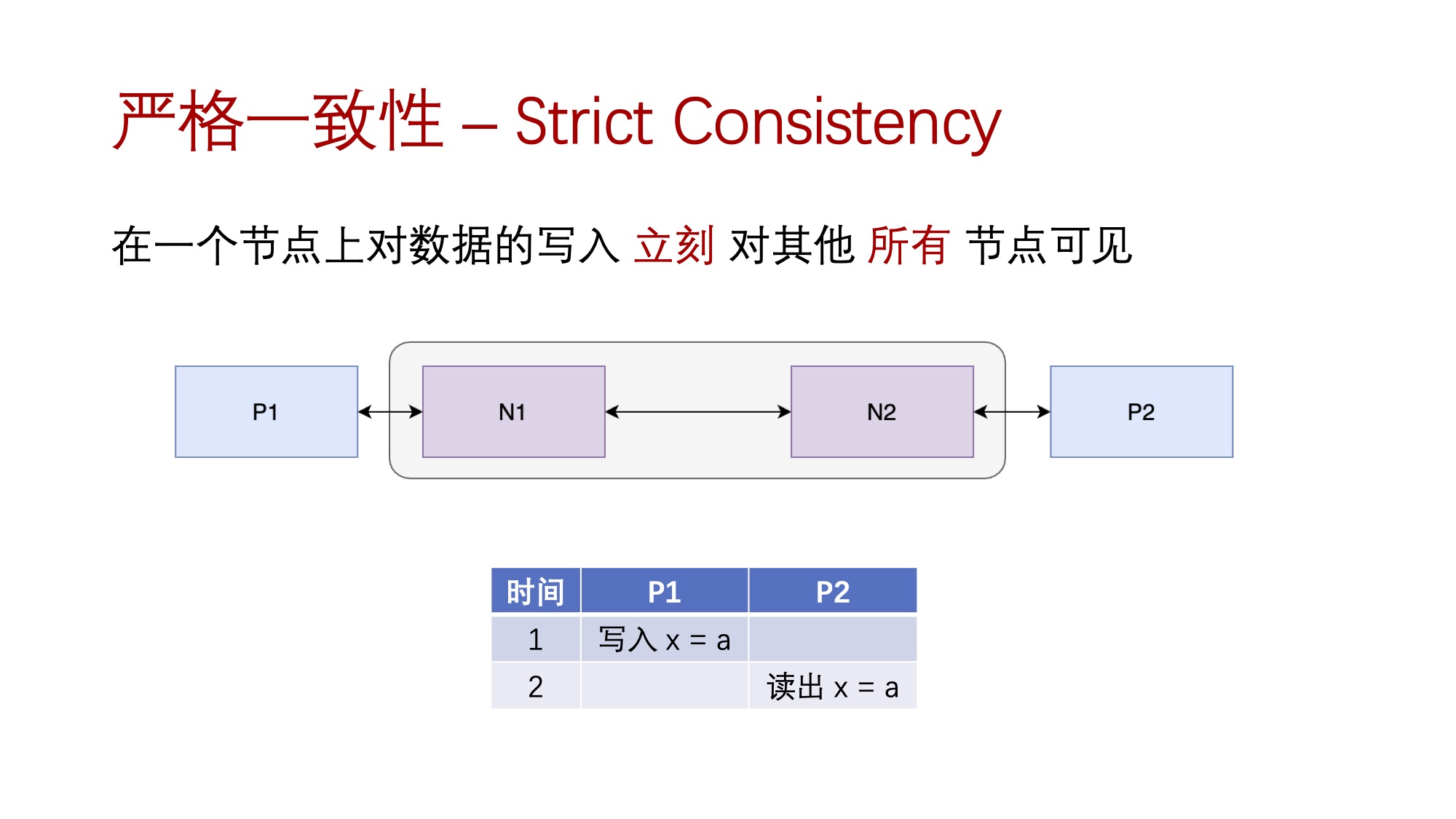
严格一致性是最严格也是最理想的一致性模型,它要求分布式系统时刻保持一致。说它是一种理想的一致性模型,是因为系统如果要实现严格一致性的话所需要承担的 节点间通信成本 是非常大的。我们假想一个场景,有数据备份 $R$,客户端 P 以 $N$ 次每秒的频率读取数据备份 $R$,其他客户端以 $M$ 次每秒的频率更新数据备份 $R$。若有 $N << M$,意味着数据备份 $R$ 有大量的历史版本实际上不会被客户端 P 观察到,而严格一致性依然要求系统对这些历史变更进行完整的同步,实际上这就引入了不少的浪费,因为我们知道要讲数据变更在多个节点间同步是需要消耗一定的计算资源及网络资源的。
综上所述,严格一致性是最严格也是最理想的一致性模型,它缺少足够的现实意义,在于系统要实现严格一致性需要付出不必要的高昂成本。为了在一致性和性能之间达到良好的平衡,现代分布式系统通常会选择 牺牲一定的一致性 从而换取足够的性能。但这些系统依然希望能够支持到 CAP 理论中的 C,即时刻能为外部客户端提供一致的数据视图。要做到这一点,现代分布式系统就会对客户端发起请求的方式提出一定的约束。

讲到这里,我们就可以来介绍一下,什么是一致性模型了。各种各样的 一致性模型(Consistency Model)实际上描述了客户端和系统交互的一系列规则,客户端遵循这些规则才能始终从系统获得一致、可预测的数据响应。客户端必须遵循一致性模型所设定的规则,否则可能会从系统处得到预期外的结果,而这种情况下应当被视为客户端有 Bug。
严格一致性是对客户端最友好的一致性模型:它不要求客户端留意任何规则,允许客户端在任何时刻发起任意请求,系统依然能返回一致的结果。

在前面我们也提到,系统的一致性与性能之间是存在本质矛盾的,强一致性保证也会影响系统的可扩展性,在于:
- 数据备份间的同步会消耗系统对外的请求处理能力
- 越多的系统节点意味着越高的同步成本:数据备份同步本身就缺乏足够的可扩展性!
现代的分布式系统通常都会基于主要针对支持的使用场景和数据使用模式,来 放松 自己对外的一致性保证,由客户端应用来 容忍 特定的不一致行为,进而换取足够的性能。也是由此,业界诞生出了不同类型的一致性模型和分布式系统。
常见的一致性模型
在这一节中,我将给大家介绍几种常见的一致性模型。
严格一致性 - Strict Consistency
在上一节中我们已经介绍过了严格一致性模型,它要求系统接收到的写入操作要 立刻 在 所有 节点上可见。

同样,如上一节所述,严格一致性是最严格也是最理想的一致性模型,它缺少足够的现实意义。
顺序一致性 - Sequential Consistency
顺序一致性相比之下会比严格一致性稍微放松一些,它不要求写入操作立刻在所有节点上可见,仅要求 不同的写入操作以相同的顺序在各个节点上可见。
例如我们看下面这个操作时序图:
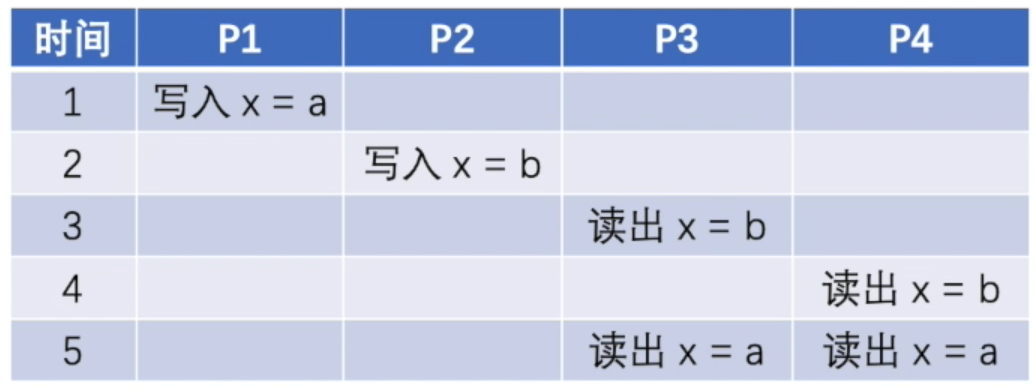
节点 P1 和 P2 分别在时间点 1 和 2 完成了 $x = a$ 和 $x = b$ 的写入。然后我们可以看到,节点 P3 和 P4 均是先能够读出 $x = b$,再能够读出 $x = a$。尽管看起来与最初写入的顺序不同,但我们看到两次写入操作都是以先 $b$ 后 $a$ 的顺序在 P3 P4 节点上可见,因此这样的时序是满足顺序一致性的。
因果一致性 - Causal Consistency
因果一致性是比顺序一致性更加放松的一致性模型,它要求 存在因果关系的写入操作以相同的顺序在各个节点上可见。
对于如何判断两个操作间是否存在因果关系,不同的分布式系统可能有不同的设定。通常会把同一个节点先后完成的操作视为存在因果关系。
例如我们看下面这个操作时序图:
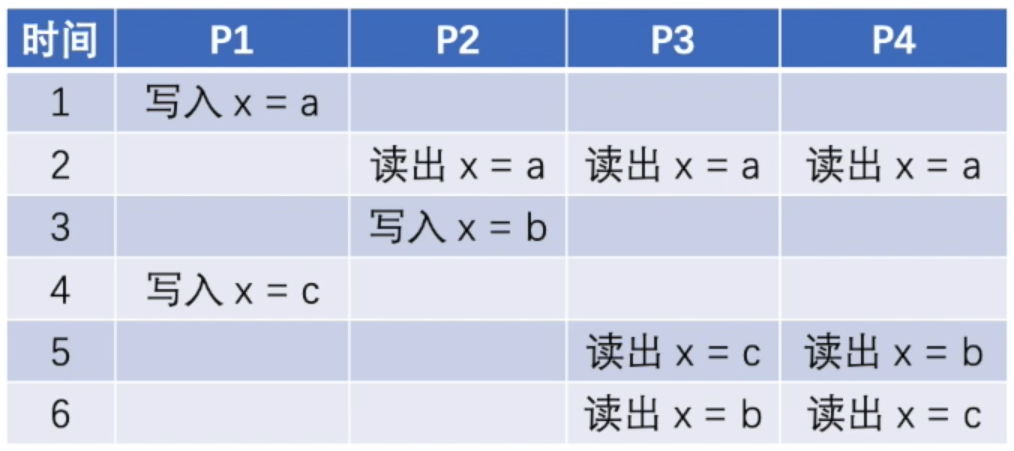
先看节点 P1,它先后完成了 $x = a$ 和 $x = c$ 的写入操作,两次操作视为存在因果关系,因此其他节点需要满足先观察到 $x = a$ 再观察到 $x = c$。再看节点 P2,它先是读出了 $x = a$,然后再写入了 $x = b$,此时依然需要将这两次操作视为存在因果关系,由此其他节点需要满足先观察到 $x = a$ 再观察到 $x = b$。至此,我们已有结论,其他节点必须先观察到 $x = a$,再观察到 $x = b$ 和 $x = c$,但后两次数据变更的可见顺序没有要求,上图中的 P3 和 P4 就代表了这两种合法的数据变更同步顺序,因此上图的时序是满足因果一致性的。
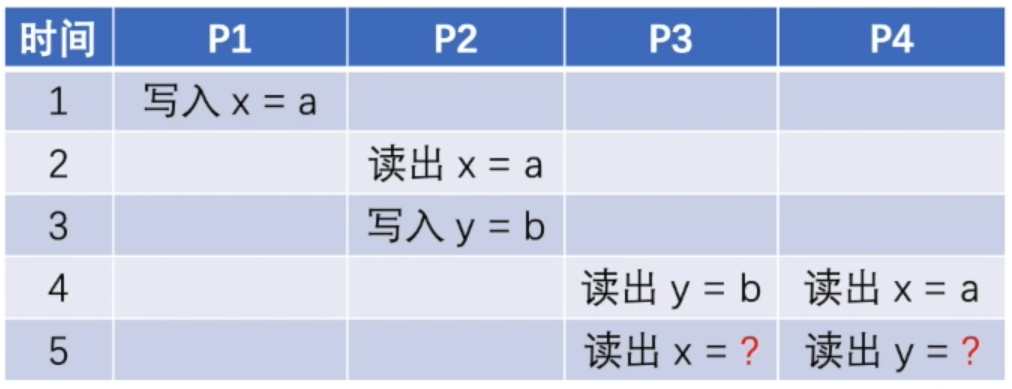
思考题 1:对于一个满足因果一致性的系统,有下面这张操作时序图
请问:
- 节点 P3 在时间点 5 读出的 $x$ 值是?
- 节点 P4 在时间点 5 读出的 $y$ 值是?
思考题 2:满足顺序一致性的分布式系统是否一定满足因果一致性?
最终一致性 - Eventual Consistency
最终一致性是最弱的一致性模型,它既不保证系统完成数据一致的时延,也不保证写入可见的顺序,仅保证系统 总能在某一时间后 收敛到一致。

线性一致性 - Linearizability
最后我们要介绍的是线性一致性。线性一致性在定义上对顺序一致性模型针对现实场景进行了一定的补充和扩展,包括:
- 加入了对来自不同节点的 并发写入 的考虑
- 加入了对 不同操作的全局顺序 的考虑
可以说,线性一致性是一种更具现实意义的顺序一致性模型,而我们通常会将满足线性一致性的分布式系统视为满足 CAP 理论中的 C。例如,在我此前解析过的 Raft 论文 的第八章就明确提到了 Raft 为客户端提供线性一致性的保证。
与上述几种较理论的一致性模型不同,线性一致性会将一次操作拆分为 客户端发起调用 和 系统返回响应 两个瞬时事件,两次事件的发生存在先后的时间差,而操作将在这两个事件之间的某一个时间点上实际生效。
例如我们来看下面这样一张 FIFO 队列的线性一致操作时序图(以水平为时间轴,不同的操作行属于不同的节点):

首先我们可以留意到,这张时序图与以往的有所不同,在于来自两个客户端的入队操作同时发生。考虑到线性一致性认为操作会在操作开始和结束之间的某一时刻上生效,因此对于这个时序,两次入队操作的两种先后次序都是可能的。
我们再来看这样一张时序图:

我们可以看到,在这张时序图中,P2 节点在 P1 节点完成最初的入队 $a$ 操作后才发起入队 $b$ 的操作,$a$ 实际入队的时间点必然早于 $b$,因此 P1 节点后续先出队 $b$ 是不合理的,这张时序图也是不满足线性一致性的。
这也就是为什么说,线性一致性模型考虑了不同操作的全局顺序。我们可以看到,尽管操作来自两个不同的节点,但从一个全局时钟的视角来看,P2 节点入队 $b$ 的操作是晚于 P1 节点入队 $a$ 的操作的,因为前者的开始时间晚于后者的结束时间,而线性一致性则要求对于这样的操作,系统需要保留它们的先后生效顺序。
保留操作的全局顺序的好处在于,对于同一个客户端来说,它可以将自己不同的操作派发给不同的系统节点处理,只要它串行地进行操作,这些操作在系统上就会以相同的顺序生效;而对于仅满足因果一致性的系统来说,要做到这一点会要求客户端始终将自己的操作发送给同一个系统节点处理。
面向客户端的一致性模型
前面我们提到的几种一致性模型,都属于 面向服务端的一致性模型:它们都是从服务端的视角出发,要求系统对不同节点/并发访问的客户端提供特定的一致性保证。
除了面向服务端的一致性模型以外,还有 面向客户端的一致性模型:它们是从单个客户端的视角出发,要求系统对同一个客户端先后发起的读写操作提供特定的一致性保证。
面向客户端的一致性模型包括 4 种:
- 单调读一致(Monotonic Reads):客户端后续发起的 读操作 能够感知到先前 读取 到的或更新的版本
- 写读一致(Read Your Writes):客户端后续发起的 读操作 能够感知到先前 写入 的或更新的版本
- 读写一致(Writes Follow Reads):客户端后续发起的 写操作 能够感知到先前 读取 到或更新的版本
- 单调写一致(Monotonic Writes):客户端后续发起的 写操作 能够感知到先前 写入 的或更新的版本

与面向服务端一致性模型不同的是,上述 4 中面向客户端的一致性模型在定义上互无交集,分布式系统可以选择提供上述的任意多个面向客户端一致性保证。以 MongoDB 的 可调一致性 为例,甚至可以让客户端通过不同的查询参数配置选择不同的客户端一致性保证,详见 https://docs.mongodb.com/manual/core/causal-consistency-read-write-concerns/。
结语
在这篇文章中,我梳理了以往我做过的一次技术分享的内容,给大家介绍了什么是一致性模型,以及几种常见的一致性模型,想必对于大家后续阅读更多的分布式系统论文会有不少的帮助。
附录:思考题答案
思考题 1:对于一个满足因果一致性的系统,有下面这张操作时序图
请问:
- 节点 P3 在时间点 5 读出的 $x$ 值是?
- 节点 P4 在时间点 5 读出的 $y$ 值是?
P3 读出的是 $x = a$,P4 读出的 $y$ 值不确定。
基于节点 P2 的时序,我们可以知道 P3 P4 会先观察到 $x = a$,再观察到 $y = b$。P3 在时间点 4 的读取到 $y = b$,意味着此时它已经能观察到 $x = a$,因此它在时间点 5 将读出 $x$ 的值为 $a$。P4 在时间点 4 读取到了 $x = a$,但缺少足够的信息判断 $y = b$ 的变更是否已在 P4 所连接的节点上可见,因此无法判断 P4 在时间点 5 将读出什么 $y$ 值。
思考题 2:满足顺序一致性的分布式系统是否一定满足因果一致性?
是。回忆因果一致性要求在同一节点上完成的操作要以相同的顺序在其他节点上可见,而顺序一致性则要求所有操作要以相同的顺序在所有节点上可见。在一个满足顺序一致性的系统中,如果我们只考虑它其中的某个节点,先后完成了一些操作,这些操作是需要以相同的顺序在其他节点上可见的,因为这些操作已经以该顺序在该节点上可见,顺序一致性的保证要求了这些操作需要以相同的顺序在其他节点上可见,这恰好就满足了因果一致性的要求。由此可见,在定义上,顺序一致性是包含因果一致性的。

