Spark RDD 论文简析
遥想我第一次参加实习的时候,我接手的第一个项目便是 Spark 插件的开发。当时为了做好这个工作,自己看了 Spark RDD 和 SparkSQL 的论文,还在阅读 Spark 源码的同时写了好多 Spark 源码分析的文章。过去了那么久,现在便趁着学习 MIT 6.824 的机会,再来整理一下 Spark RDD 论文的内容吧。
本文由我按照 MIT 6.824 的课程安排阅读 Spark RDD 的论文以及相关课程资料并总结而来,内容会更偏向于从科研的角度介绍 Spark RDD 诞生时所需要解决的问题以及对其基本工作方式的简单介绍。
背景
在 Apache Spark 广泛使用以前,业界主要使用 Hadoop MapReduce 来对大数据进行分布式处理。诚然 Hadoop MapReduce 为企业及组织利用大量普通消费级机器组建集群进行数据处理成为可能,但随着需求的不断扩展,Hadoop MapReduce 也存在着这样那样的局限:
- MapReduce 编程模型的表达能力有限,仅靠 MapReduce 难以实现部分算法
- 对分布式内存资源的使用方式有限,使得其难以满足最近大量出现的需要复用中间结果的计算流程,包括:
- 如迭代式机器学习算法及图算法
- 交互式数据挖掘
Spark RDD 作为一个分布式内存资源抽象便致力于解决 Hadoop MapReduce 的上述问题:
- 通过对分布式集群的内存资源进行抽象,允许程序高效复用已有的中间结果
- 提供比 MapReduce 更灵活的编程模型,兼容更多的高级算法
接下来我们便详细说说 Spark RDD 是如何达成上述目标的。
RDD:分布式内存资源抽象
RDD(Resilient Distributed Dataset,弹性分布式数据集)本质上是一种只读、分片的记录集合,只能由支持的所数据源或是由其他 RDD 经过一定的转换(Transformation)来产生。通过由用户构建 RDD 间组成的产生关系图,每个 RDD 都能记录到自己是如何由还位于持久化存储中的源数据计算得出的,即其血统(Lineage)。
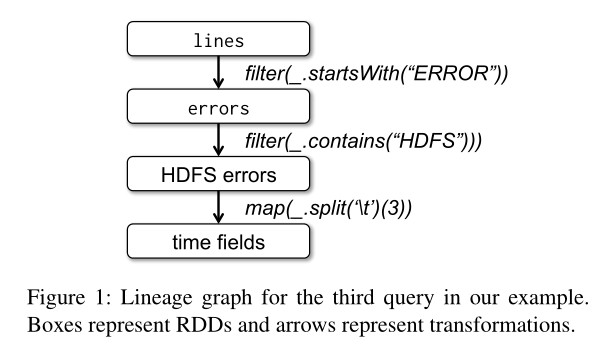
相比于 RDD 只能通过粗粒度的“转换”来创建(或是说写入数据),分布式共享内存(Distributed Shared Memory,DSM)是另一种分布式系统常用的分布式内存抽象模型:应用在使用分布式共享内存时可以在一个全局可见的地址空间中进行随机的读写操作。类似的系统包括了一些常见的分布式内存数据库(如 Redis、Memcached)。RDD 产生的方式限制了其只适用于那些只会进行批量数据写入的应用程序,但却使得 RDD 可以使用更为高效的高可用机制。
除了 Transformation 以外,Spark 还为 RDD 提供了 Action,可对 RDD 进行计算操作并把一个结果值返回给客户端,或是将 RDD 里的数据写出到外部存储。

Transformation 与 Action 的区别还在于,对 RDD 进行 Transformation 并不会触发计算:Transformation 方法所产生的 RDD 对象只会记录住该 RDD 所依赖的 RDD 以及计算产生该 RDD 的数据的方式;只有在用户进行 Action 操作时,Spark 才会调度 RDD 计算任务,依次为各个 RDD 计算数据。
RDD 具体实现与计算调度
前面我们提到,RDD 在物理形式上是分片的,其完整数据被分散在集群内若干机器的内存上。当用户通过 Transformation 创建出新的 RDD 后,新的 RDD 与原本的 RDD 便形成了依赖关系。根据用户所选 Transformation 操作的不同,RDD 间的依赖关系可以被分为两种:
- 窄依赖(Narrow Dependency):父 RDD 的每个分片至多被子 RDD 中的一个分片所依赖
- 宽依赖(Wide Dependency):父 RDD 中的分片可能被子 RDD 中的多个分片所依赖
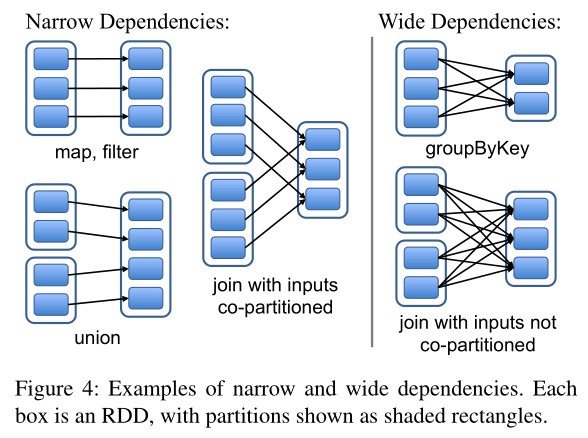
通过将窄依赖从宽依赖中区分出来,Spark 便可以针对 RDD 窄依赖进行一定的优化。首先,窄依赖使得位于该依赖链上的 RDD 计算操作可以被安排到同一个集群节点上流水线进行;其次,在节点失效需要恢复 RDD 时,Spark 只需要恢复父 RDD 中的对应分片即可,恢复父分片时还能将不同父分片的恢复任务调度到不同的节点上并发进行。
总的来说,一个 RDD 由以下几部分组成:
- 其分片集合
- 其父 RDD 集合
- 计算产生该 RDD 的方式
- 描述该 RDD 所包含数据的模式、分片方式、存储位置偏好等信息的元数据
在用户调用 Action 方法触发 RDD 计算时,Spark 会按照定义好的 RDD 依赖关系绘制出完整的 RDD 血统图,并根据图中各节点间依赖关系的不同对计算过程进行切分:
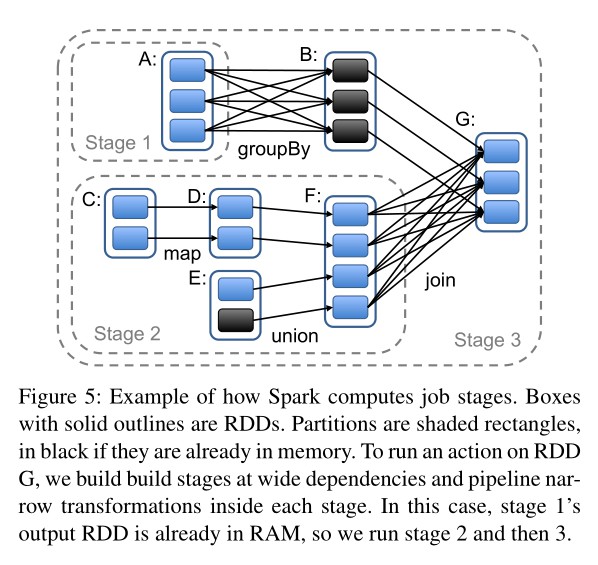
简单来说,Spark 会把尽可能多的可以流水线执行的窄依赖 Transformation 放到同一个 Job Stage 中,而 Job Stage 之间则要求集群对数据进行 Shuffle。Job Stage 划分完毕后,Spark 便会为每个 Partition 生成计算任务(Task)并调度到集群节点上运行。
在调度 Task 时,Spark 也会考虑计算该 Partition 所需的数据的位置:例如,如果 RDD 是从 HDFS 中读出数据,那么 Partition 的计算就会尽可能被分配到持有对应 HDFS Block 的节点上;或者,如果 Spark 已经将父 RDD 持有在内存中,子 Partition 的计算也会被尽可能分配到持有对应父 Partition 的节点上。对于不同 Job Stage 之间的 Data Shuffle,目前 Spark 采取与 MapReduce 相同的策略,会把中间结果持久化到节点的本地存储中,以简化失效恢复的过程。
当 Task 所在的节点失效时,只要该 Task 所属 Job Stage 的父 Job Stage 数据仍可用,Spark 只要将该 Task 调度到另一个节点上重新运行即可。如果父 Job Stage 的数据也已经不可用了,那么 Spark 就会重新提交一个计算父 Job Stage 数据的 Task,以完成恢复。有趣的是,从论文来看,Spark 当时还没有考虑调度模块本身的高可用,不过调度模块持有的状态只有 RDD 的血统图和 Task 分配情况,通过状态备份的方式实现高可用也是十分直观的。
结语
总的来说,Spark RDD 的亮点在于如下两点:
- 确定且基于血统图的数据恢复重计算过程
- 面向记录集合的转换 API
比起类似于分布式内存数据库的那种分布式共享内存模型,Spark RDD 巧妙地利用了其不可变和血统纪录的特性实现了对分布式内存资源的抽象,很好地支持了批处理程序的使用场景,同时大大简化了节点失效后的数据恢复过程。
同时,我们也应该意识到,Spark 是对 MapReduce 的一种补充而不是替代:将那些能够已有的能够很好契合 MapReduce 模型的计算作业迁移到 Spark 上不会收获太多的好处(例如普通的 ETL 作业)。除外,RDD 本身在 Spark 生态中也渐渐变得落伍,Spark 也逐渐转向使用从 SparkSQL 开始引入的 DataFrame 模型了。后续有时间的话我也许也会再总结一下 SparkSQL 的论文。
不管怎么说,Spark RDD 依然是通过很简单的方式解决了大数据计算领域中的一大痛点,阅读其论文也是一次相当不错的 Case Study。
Spark RDD 论文简析

