Spark SQL 论文简述
先前在读过 Spark RDD 的论文后,我从 MIT 6.824 的课程笔记中了解到,RDD 在 Apache Spark 中已经不那么常用,开发重心渐渐转移到了 Spark SQL 的 DataFrame API 上。在我第一次实习的时候其实也有读过 Spark SQL 的论文,那这次就重新读读这篇论文,总结一下吧。
背景
如 Hadoop MapReduce、Spark RDD 等分布式计算引擎所提供的编程接口尽管有效,但都相对底层、过程式,用户要让自己的程序有较好的性能需要自行进行较为复杂的优化。由此,如 Hive、Pig 等新系统开始选择通过暴露如 SQL 等声明式的查询接口来让程序的自动优化变得可能。
仅仅使用 SQL 进行查询是无法满足所有需求的。常见的不足包括以下两点:
- 用户会需要对大量的数据进行 ETL 操作,而这些源数据往往只是半结构化甚至是非结构化的,这就使得用户需要能够自行编写代码
- SQL 查询无法表达更为复杂的计算逻辑,如机器学习算法和图处理算法等
实际上,Spark SQL 并不只是 SQL-on-Spark 的定位 —— 更早之前已有一个叫做 Shark 的框架做了这件事。为了解决以上问题,Spark SQL 的设计目标包括以下:
- 通过程序员友好的 API 提供针对 RDD 及外部数据源的关系型处理
- 利用已有的 DBMS 技术提供较高的处理性能
- 支持更多的外部数据源,包括半结构化与非结构化的数据源
- 支持对高级分析算法的扩展,包括图处理算法及机器学习算法
为了实现以上目标,Spark SQL 主要借助了两大核心组件:DataFrame API 和 Catalyst。
DataFrame API
DataFrame 是由拥有统一结构的记录所组成的集合,逻辑上等价于关系型数据库中的一张表。与 RDD 不同的地方在于,DataFrame 还会记录数据的模式信息。
DataFrame 的 API 支持过去 Spark 已有的过程式 API,还加入了新的关系型操作 API,如 select、groupBy 等。用户可以通过编写代码使用 DataFrame API,也可以通过 JDBC/ODBC 等方式启动 Spark SQL 查询。
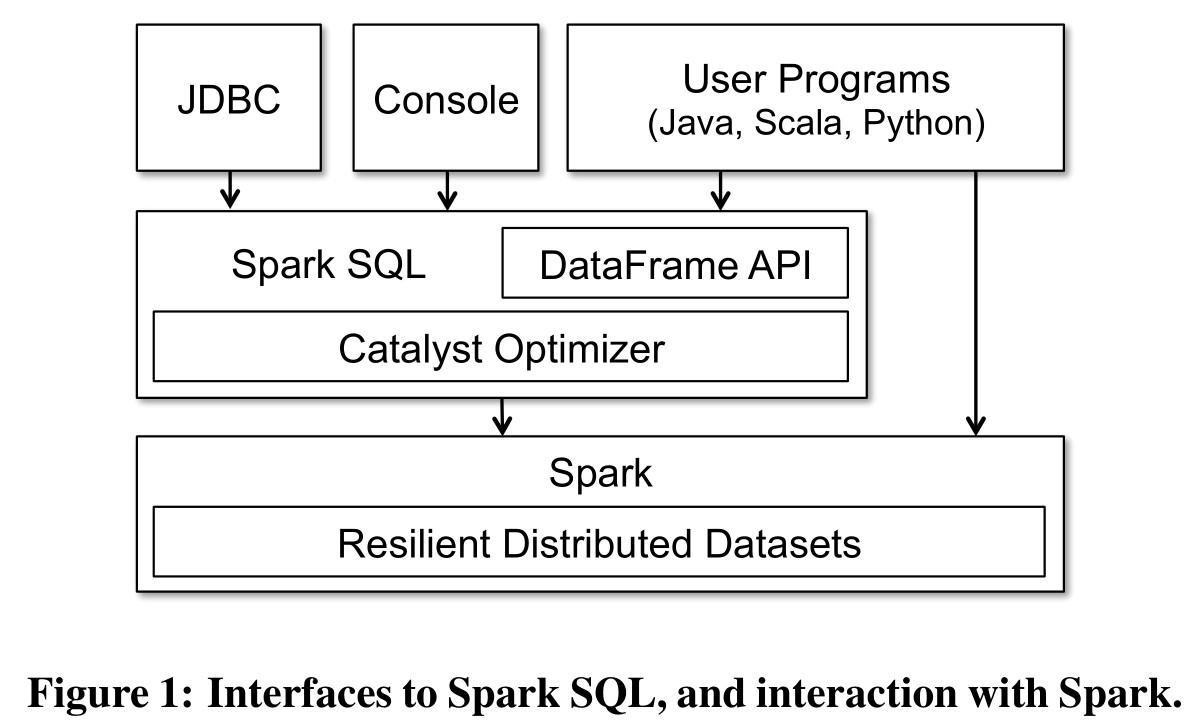
在实现上,每个 DataFrame 对象都代表着计算出对应数据集的 Logical Plan。和 RDD 类似,DataFrame 的数据计算也是延后的,这使得 Spark SQL 能够针对构建 DataFrame 的完整操作链对计算进行优化。最终,DataFrame 会经过 Catalyst 优化后转换为对应的 RDD 计算流程,使用已有的 Spark RDD 计算引擎完成计算。
除外,由于 DataFrame 拥有数据模式信息,在对 DataFrame 进行缓存时,Spark SQL 会将数据转换为更加紧凑的列式格式,相比于 RDD 直接缓存 JVM 对象有着小得多的内存占用。
Catalyst
Catalyst 是一个可扩展的查询优化器。从上面的 Spark SQL 架构图可以看出,DataFrame 对应的 Logical Plan 会经过 Catalyst 进行优化、转换,最终变成对应的 RDD Physical Plan,再提交到 Spark 上进行计算。
Catalyst 对 DataFrame 的查询优化可以分为以下几个步骤:
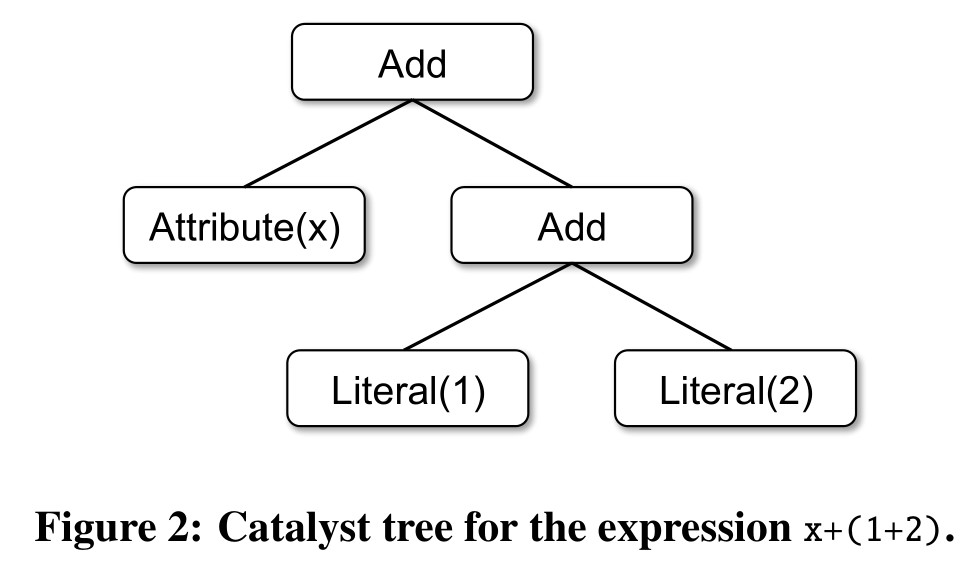
首先,用户通过 DataFrame API 层层构建出的 DataFrame 对象中的信息可以构建出计算出对应数据的操作的 AST(Abstract Syntax Tree,抽象语法树)。如表达式 x + (1 + 2) 即可解析为如下 AST:
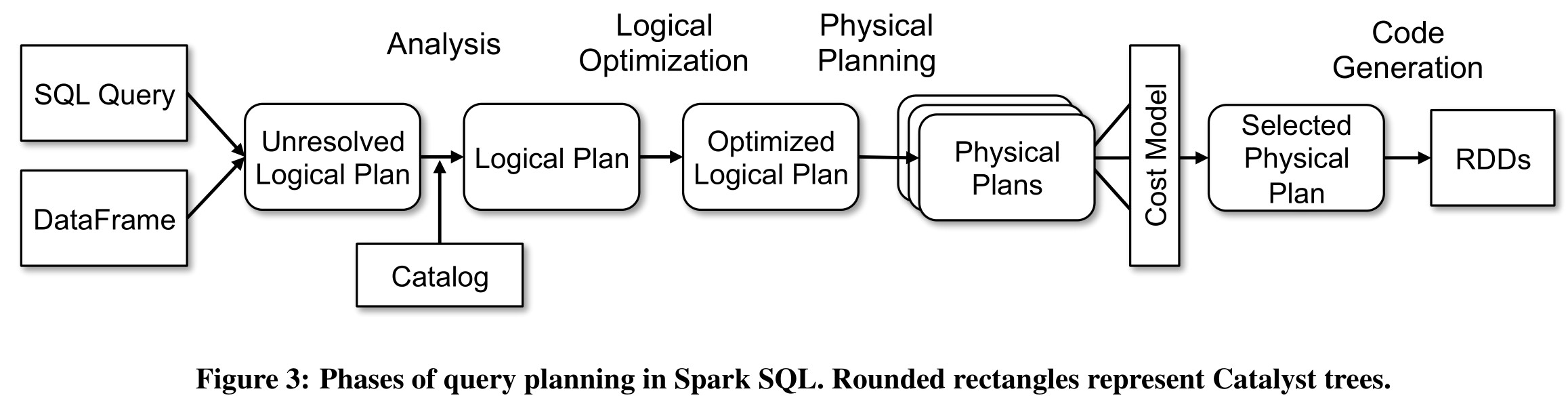
Catalyst 的查询优化从用户通过 Scala 代码构建的 DataFrame 对象或是 SQL 解析器返回的 AST 开始。该输入结构被统称为 Unresolved Logical Plan,源于树中部分对属性/表的引用是未解析的(Unresolved,即 Spark 暂不知晓其所引用的属性、表为何)。那么第一步,Analysis,便是借助 Spark SQL 的 Catalog 对象以及其他外部数据源中存储的信息对这些引用进行解析。解析后便得到了 Logical Plan。
此时的 Logical Plan 代表的便是计算出 DataFrame 所指带数据的逻辑执行计划,其中已载入所有源数据的模式信息。Catalyst 的下一项处理便是 Logical Optimization,对该逻辑执行计划进行优化。
Catalyst 对逻辑执行计划所进行的优化过程是 Rule-based 的:Catalyst 会不断地递归整棵 Logical Plan 树,将其结构与预设的优化规则进行匹配,并对匹配的子树进行对应的转换。Catalyst 所使用的优化规则在其他关系型数据库中也十分常见,包括常量合并、条件过滤下推等。
值得一提的是,Catalyst 此部分的实现代码大量使用了 Scala 的 Pattern Matching 特性,使得优化规则的表达变得十分简洁清晰。这样的特性也使得其他代码贡献者能够以更低成本对 Catalyst 进行扩展,加入更多优化规则。
第三步,Physical Planning,Catalyst 便会将 Optimized Logical Plan 转换为若干个对应的 Physical Plan,并根据它们的计算代价选出最优的 Physical Plan(Cost-based 优化):例如,对于 JOIN 操作,此步就会根据左右表大小的不同选取出不同的 JOIN 算法。
除外,Catalyst 在 Physical Planning 阶段会利用更多由外部数据源提供的统计信息,除了源数据的预计大小外还有外部数据源所支持的操作等。有了这些信息,Catalyst 在该阶段也会进行一些额外的 Rule-based 优化,应用那些能够利用这些信息的优化规则,例如将条件过滤、字段投影等操作下推到外部数据源中执行。
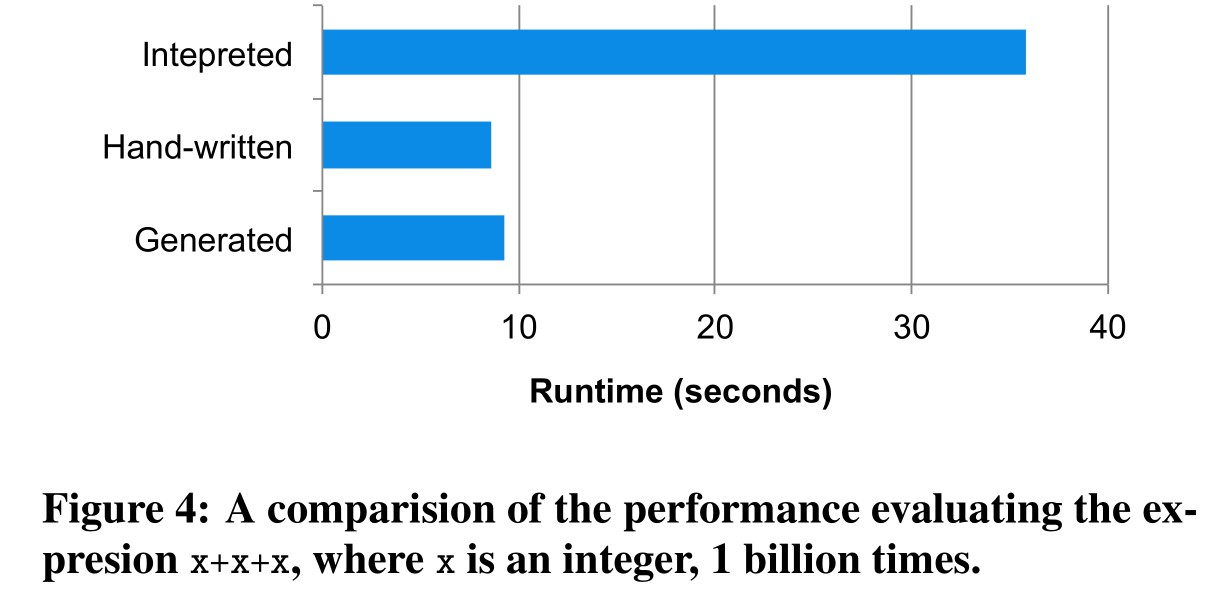
最后,Catalyst 会对选取出的最优 Physical Planning 使用 Scala 提供的 Quasiquotes 功能,生成出对应的 RDD 计算代码,并提交到 Spark 引擎上执行。实际上,Spark SQL 大可以将整棵 Physical Planning 树提交执行,但 Catalyst 还是选择了转换为对应的 Scala 代码后再提交,最主要的的原因是这使得计算时不会因为树的层级产生多余的中间对象,极大地提高了计算的效率。从 Spark SQL 论文中展示的性能对比来看,代码生成使得程序在执行时的效率与人类手写对应 Scala 代码的效率相近,远高于直接执行未转换的操作树。
文中还提及了很多使用 Scala Quasiquotes 所带来的好处,可惜笔者并未学习过 Scala 的这项功能,无法理解这部分细节。感兴趣的读者可自行查阅原文。
结语
总的来说,Spark SQL 的论文并不像是一篇学术论文,文中大量描述了 Spark SQL 的实现细节,更像是一篇工程论文。原文提及了很多工程实现上的取舍及原因,如 Scala 作为函数式语言天生适合用于编写编译器,以及 Catalyst 巧用 Scala 的特性使得其他代码贡献者能够很方便地为 Catalyst 添加更多的优化规则等。实际上,Catalyst 作为 Scala 仅有的一个产品级查询优化器(据论文所说),其设计还是很值得我们去学习的。
Spark SQL 论文简述

