classDataFrameprivate[sql]( @transient val sqlContext: SQLContext, @DeveloperApi @transient val queryExecution: SQLContext#QueryExecution) extendsRDDApi[Row] withSerializable {
/** * A constructor that automatically analyzes the logical plan. * * This reports error eagerly as the [[DataFrame]] is constructed, unless * [[SQLConf.dataFrameEagerAnalysis]] is turned off. */ defthis(sqlContext: SQLContext, logicalPlan: LogicalPlan) = { this(sqlContext, { val qe = sqlContext.executePlan(logicalPlan) if (sqlContext.conf.dataFrameEagerAnalysis) { qe.assertAnalyzed() // This should force analysis and throw errors if there are any } qe }) } // ... }
/** * :: DeveloperApi :: * The primary workflow for executing relational queries using Spark. Designed to allow easy * access to the intermediate phases of query execution for developers. */ @DeveloperApi protected[sql] classQueryExecution(val logical: LogicalPlan) { defassertAnalyzed(): Unit = analyzer.checkAnalysis(analyzed)
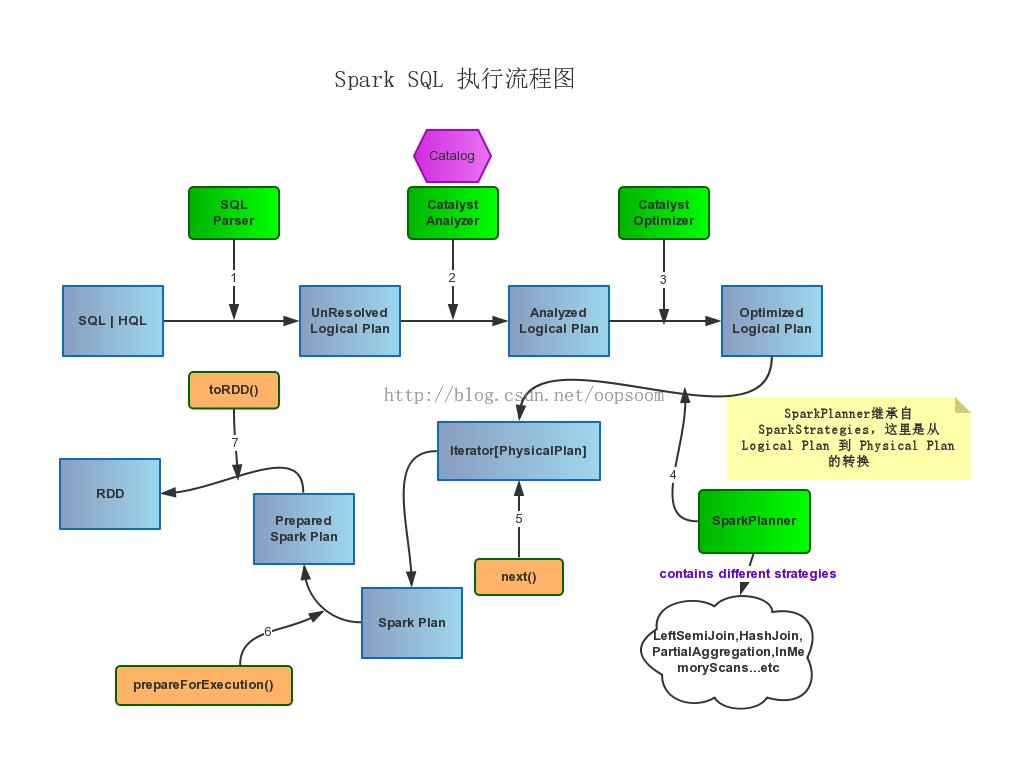
// Unresolved Logical Plan -> Analyzed Logical Plan -> Optimized Logical Plan // -> Physical Plan -> Executed Physical Plan -> RDD
// 分析 unresolved 的 LogicalPlan,得到 Analyzed Logical Plan // Unresolved Logical Plan -> Analyzed Logical Plan lazyval analyzed: LogicalPlan = analyzer.execute(logical)
// 将 LogicalPlan 中的结点尽可能地替换为 cache 中的结果,得到 Analyzed Logical Plan with Cached Data lazyval withCachedData: LogicalPlan = { assertAnalyzed() cacheManager.useCachedData(analyzed) }
// 对 Analyzed Logical Plan with Cached Data 进行优化,得到 Optimized Logical Plan // Analyzed Logical Plan -> Optimized Logical Plan lazyval optimizedPlan: LogicalPlan = optimizer.execute(withCachedData)
// 生成 PhysicalPlan // Optimized Logical Plan -> Physical Plan lazyval sparkPlan: SparkPlan = { SparkPlan.currentContext.set(self) planner.plan(optimizedPlan).next() } // executedPlan should not be used to initialize any SparkPlan. It should be // only used for execution. // 准备好的 PhysicalPlan lazyval executedPlan: SparkPlan = prepareForExecution.execute(sparkPlan)
/** Internal version of the RDD. Avoids copies and has no schema */ // 执行并返回结果 lazyval toRdd: RDD[Row] = executedPlan.execute()
// TODO previously will output RDD details by run (${stringOrError(toRdd.toDebugString)}) // however, the `toRdd` will cause the real execution, which is not what we want. // We need to think about how to avoid the side effect. s"""== Parsed Logical Plan == |${stringOrError(logical)} |== Analyzed Logical Plan == |${stringOrError(output)} |${stringOrError(analyzed)} |== Optimized Logical Plan == |${stringOrError(optimizedPlan)} |== Physical Plan == |${stringOrError(executedPlan)} |Code Generation: ${stringOrError(executedPlan.codegenEnabled)} |== RDD == """.stripMargin.trim } }