在上一篇文章 中,我们了解了 SparkSQL 如何将各式语句分别委派到三个不同的 Parser 中进行解析,并返回一个 Unresolved Logical Plan。
在这篇文章中,我打算在讲解 Analyzer 之前先为大家讲解一下 Spark 里的 LogicalPlan 数据结构。
TreeNode 在进入 Analyzer 的学习前,我们不妨先花点时间了解一下这个 LogicalPlan 是一个怎么样的数据结构,为何 Spark 可以在产生一个这样的实例后还能进行如此多的优化操作。
实际上,有学习过数据库原理,或者有看过我之前说的这篇论文 ,也基本能猜到,LogicalPlan 这个类本质上是一棵抽象语法树(AST)。我们先来看看核心类 LogicalPlan:
1 2 3 4 5 6 7 8 9 10 abstract class LogicalPlan extends QueryPlan [LogicalPlan ] with Logging self: Product => override protected def statePrefix if (!resolved) "'" else super .statePrefix }
LogicalPlan 继承自 QueryPlan,但实际上 LogicalPlan 只定义了一个带有 override 关键字的方法。那么我们先不着急看 LogicalPlan,我们先去看看它的父类 QueryPlan:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 abstract class QueryPlan [PlanType <: TreeNode [PlanType ]] extends TreeNode [PlanType ] self: PlanType with Product => protected def statePrefix if (missingInput.nonEmpty && children.nonEmpty) "!" else "" override def simpleString String = statePrefix + super .simpleString }
在 QueryPlan 中,关键字 override 同样只出现了一次。我们看到之前在 LogicalPlan 出现的 statePrefix 函数,是一个和计算过程本身没啥关系的函数,我们先跳过它。我们注意到 QueryPlan 继承自 TreeNode,同时其泛型的类型参数十分有意思,而且考虑到 LogicalPlan 本身继承的父类是 QueryPlan[LogicalPlan]。这是个很有意思的类型设定,我们不妨在看过 TreeNode 以后再来仔细推敲这个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 abstract class TreeNode [BaseType <: TreeNode [BaseType ]] self: BaseType with Product => val origin: Origin = CurrentOrigin .get def children Seq [BaseType ] def fastEquals TreeNode [_]): Boolean = { this .eq(other) || this == other } def find BaseType => Boolean ): Option [BaseType ] = f(this ) match { case true => Some (this ) case false => children.foldLeft(None : Option [BaseType ]) { (l, r) => l.orElse(r.find(f)) } } def foreach BaseType => Unit ): Unit = { f(this ) children.foreach(_.foreach(f)) } def foreachUp BaseType => Unit ): Unit = { children.foreach(_.foreachUp(f)) f(this ) } def map A ](f: BaseType => A ): Seq [A ] = { val ret = new collection.mutable.ArrayBuffer [A ]() foreach(ret += f(_)) ret } def flatMap A ](f: BaseType => TraversableOnce [A ]): Seq [A ] = def collect B ](pf: PartialFunction [BaseType , B ]): Seq [B ] = def collectFirst B ](pf: PartialFunction [BaseType , B ]): Option [B ] = def mapChildren BaseType => BaseType ): this .type = def withNewChildren Seq [BaseType ]): this .type = def transform PartialFunction [BaseType , BaseType ]): BaseType = def transformDown PartialFunction [BaseType , BaseType ]): BaseType = def transformChildrenDown PartialFunction [BaseType , BaseType ]): this .type = def transformUp PartialFunction [BaseType , BaseType ]): BaseType = def transformChildrenUp PartialFunction [BaseType , BaseType ]): this .type = }
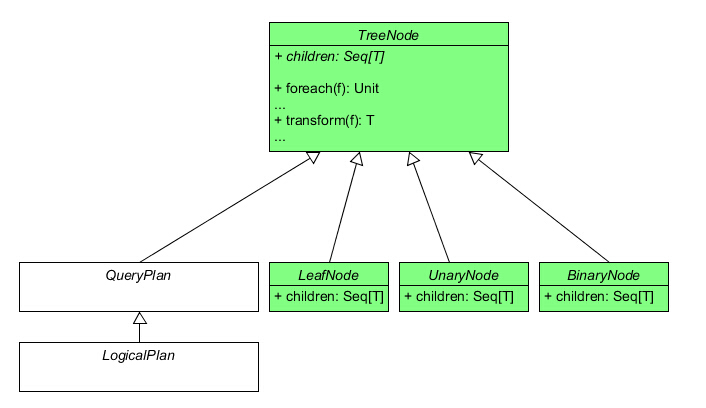
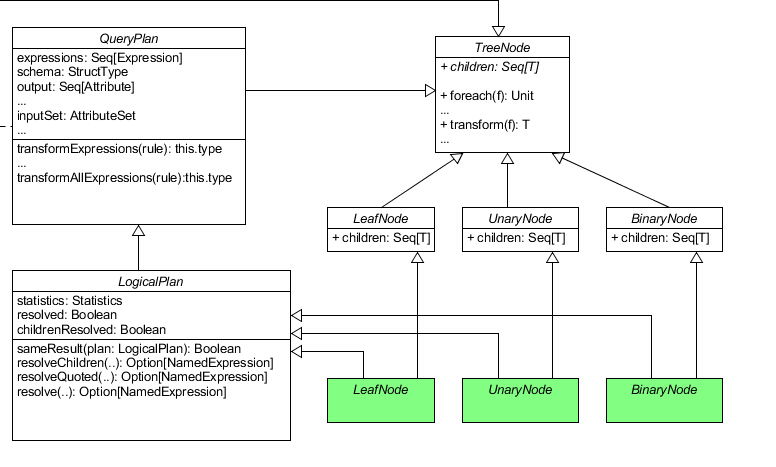
我们可以看到,除去一些比较无关痛痒的函数以外(上述源代码已忽略这些函数),TreeNode 类包含的都是一些对整棵树操作的接口。这种设计其实并不难理解。TreeNode 作为虚类,它并没有实现自己的 children 函数。但实际上同样在 TreeNode.scala 文件里,我们可以找到下述三个特质:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 trait BinaryNode [BaseType <: TreeNode [BaseType ]] def left BaseType def right BaseType def children Seq [BaseType ] = Seq (left, right) } trait LeafNode [BaseType <: TreeNode [BaseType ]] def children Seq [BaseType ] = Nil } trait UnaryNode [BaseType <: TreeNode [BaseType ]] def child BaseType def children Seq [BaseType ] = child :: Nil }
这里就定义了一棵树中的所有节点类型,包括有两个子节点的二元节点 BinaryNode 、只有一个子节点的一元节点 UnaryNode 以及没有子节点的叶子节点 LeafNode。每个节点特质都实现了 TreeNode 中的 children 函数。
现在我们似乎还不能直接解答 QueryPlan 奇怪的泛型类型是怎么回事,但我们可以先看看 TreeNode 的泛型类型。TreeNode[BaseType <: TreeNode[BaseType]],这个 <: TreeNode 好像有点死循环的意思。但其实看到 children 的类型是 Seq[BaseType] 就能理解,这里的 BaseType 指的是当前结点的子结点类型,它必然也应该是一个 TreeNode。
QueryPlan 我们回到 QueryPlan:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 abstract class QueryPlan [PlanType <: TreeNode [PlanType ]] extends TreeNode [PlanType ] self: PlanType with Product => def expressions Seq [Expression ] = { productIterator.flatMap { case e: Expression => e :: Nil case Some (e: Expression ) => e :: Nil case seq: Traversable [_] => seq.flatMap { case e: Expression => e :: Nil case other => Nil } case other => Nil }.toSeq } def transformExpressions PartialFunction [Expression , Expression ]): this .type = def transformExpressionsDown PartialFunction [Expression , Expression ]): this .type = def transformExpressionsUp PartialFunction [Expression , Expression ]): this .type = def transformAllExpressions PartialFunction [Expression , Expression ]): this .type = { transform { case q: QueryPlan [_] => q.transformExpressions(rule).asInstanceOf[PlanType ] }.asInstanceOf[this .type ] } lazy val schema: StructType = StructType .fromAttributes(output) def output Seq [Attribute ] def outputSet AttributeSet = AttributeSet (output) def references AttributeSet = AttributeSet (expressions.flatMap(_.references)) def inputSet AttributeSet = AttributeSet (children.flatMap(_.asInstanceOf[QueryPlan [PlanType ]].output)) def missingInput AttributeSet = (references -- inputSet).filter(_.name != VirtualColumn .groupingIdName) }
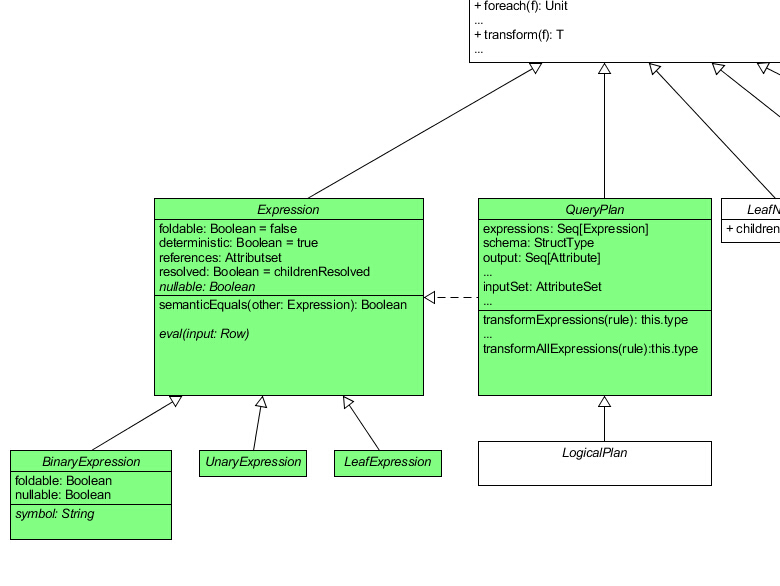
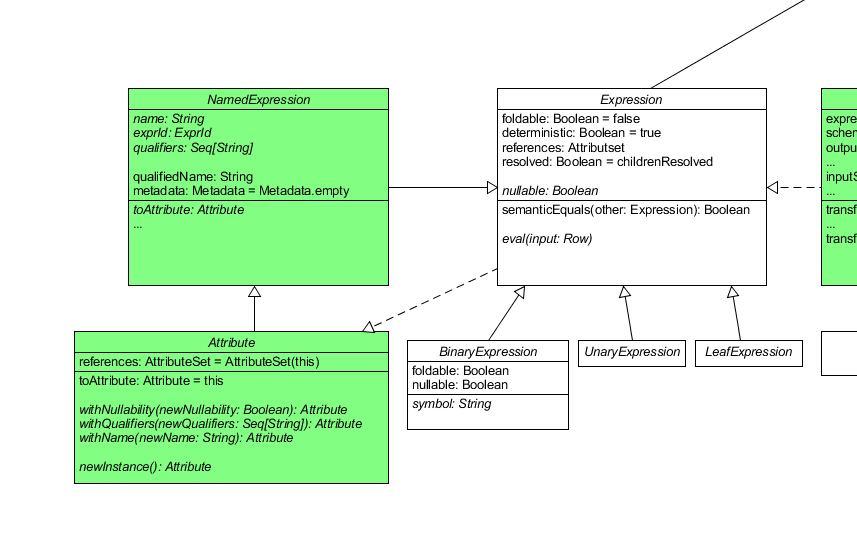
通过阅读上述代码,我们发现了 3 个新名词:schema 、 Attribute 和 Expression。schema 的类型是 StructType,使用过 SparkSQL 的读者就会明白,这个指的就是一个表的模式。Attribute 这个词曾经出现在我之前说过的那篇论文 中,指的是表中的一个字段。而 Expression 意为表达式,从 QueryPlan 中的方法可以看出这个 Expression 也是一棵树。我们可以去看看它的源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 abstract class Expression extends TreeNode [Expression ] self: Product => type EvaluatedType < Any def foldable Boolean = false def deterministic Boolean = true def nullable Boolean def references AttributeSet = AttributeSet (children.flatMap(_.references.iterator)) def eval Row = null ): EvaluatedType lazy val resolved: Boolean = childrenResolved def childrenResolved Boolean = children.forall(_.resolved) def dataType DataType def prettyString String = def semanticEquals Expression ): Boolean = } abstract class BinaryExpression extends Expression with trees .BinaryNode [Expression ] self: Product => def symbol String override def foldable Boolean = left.foldable && right.foldable override def nullable Boolean = left.nullable || right.nullable override def toString String = s"($left $symbol $right )" } abstract class UnaryExpression extends Expression with trees .UnaryNode [Expression ] self: Product => } abstract class LeafExpression extends Expression with trees .LeafNode [Expression ] self: Product => }
在学习过 TreeNode 以后,这个类就显得很好懂了。UML 类图变成了这样:
为了有助于吸收,我们可以把 QueryPlan 理解为单个执行计划,其中包括唯一的一个 SELECT 或 CREATE 等关键字。这类关键字在一条 SQL 语句中可以多次出现,因此 SparkSQL 把我们输入的语句解析为多个 QueryPlan,并以树状结构把它们组织起来,方便优化以及分清他们执行的先后顺序。在这里,QueryPlan 这棵树并不是那篇论文中提到的抽象语法树。每个查询计划对应着一句表达式,这些表达式从我们输入的 SQL 语句中拆分出来,也就是 Expression 树。一句表达式的词素被 Parser 以树状结构组织,这棵树才是那篇论文中提到的抽象语法树。不信的话,你可以在项目中找到 Literal 类(用于表示 SQL 语句中的一个常量词素),它继承自 LeafExpression。
除了 Expression,QueryPlan 还出现了 Attribute 类。也许你和我一开始一样会认为这个类的角色相当于一个 bean,实则不然。我们先来看看它的源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 abstract class Attribute extends NamedExpression self: Product => override def references AttributeSet = AttributeSet (this ) override def toAttribute Attribute = this def withNullability Boolean ): Attribute def withQualifiers Seq [String ]): Attribute def withName String ): Attribute def newInstance Attribute }
可以看到该类继承自 NamedExpression,从命名上看也能猜出这个类继承自 Expression。Attribute 类重载了 Expression 的 references 函数使其指向自身,可见 Spark 认为出现在语句中的 Attribute 本身也应该属于一个 Expression,因为在之前的分析中我们就知道,Expression 这个类不仅仅用来表达一句表达式,还用来表达表达式中的一个词素,因此这样的设计也是合情合理的。
我们再来看看 NamedExpression:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 object NamedExpression private val curId = new java.util.concurrent.atomic.AtomicLong () def newExprId ExprId = ExprId (curId.getAndIncrement()) def unapply NamedExpression ): Option [(String , DataType )] = Some (expr.name, expr.dataType) } case class ExprId (id: Long )abstract class NamedExpression extends Expression self: Product => def name String def exprId ExprId def qualifiers Seq [String ] def qualifiedName String = (qualifiers.headOption.toSeq :+ name).mkString("." ) def toAttribute Attribute def metadata Metadata = Metadata .empty protected def typeSuffix }
NamedExpression 相对于 Expression 做出的扩展并不多,仅仅是加上了 name 、exprId 、 qualifiers 、 metadata 字段以及相关方法。
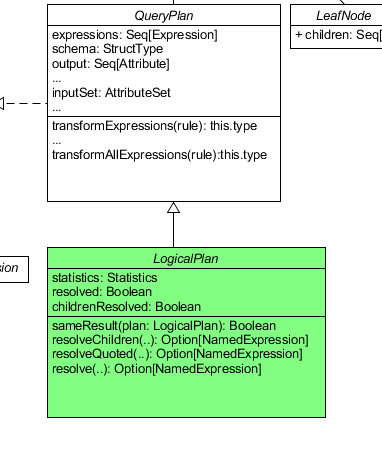
至此,QueryPlan 就全部解析完了,让我们再次回到 LogicalPlan。
LogicalPlan 我们回到梦开始的地方:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 private [sql] case class Statistics (sizeInBytes: BigInt )abstract class LogicalPlan extends QueryPlan [LogicalPlan ] with Logging self: Product => def statistics Statistics = def childrenResolved Boolean = !children.exists(!_.resolved) lazy val resolved: Boolean = !expressions.exists(!_.resolved) && childrenResolved override protected def statePrefix if (!resolved) "'" else super .statePrefix def sameResult LogicalPlan ): Boolean = def resolveChildren nameParts: Seq [String ], resolver: Resolver , throwErrors: Boolean = false ): Option [NamedExpression ] = resolve(nameParts, children.flatMap(_.output), resolver, throwErrors) def resolve nameParts: Seq [String ], resolver: Resolver , throwErrors: Boolean = false ): Option [NamedExpression ] = resolve(nameParts, output, resolver, throwErrors) def resolveQuoted name: String , resolver: Resolver ): Option [NamedExpression ] = resolve(parseAttributeName(name), resolver, true ) private def parseAttributeName String ): Seq [String ] = private def resolveAsTableColumn nameParts: Seq [String ], resolver: Resolver , attribute: Attribute ): Option [(Attribute , List [String ])] = protected def resolve nameParts: Seq [String ], input: Seq [Attribute ], resolver: Resolver , throwErrors: Boolean ): Option [NamedExpression ] = { var candidates: Seq [(Attribute , List [String ])] = { if (nameParts.length > 1 ) { input.flatMap { attr => resolveAsTableColumn(nameParts, resolver, attr) } } else { Seq .empty } } if (candidates.isEmpty) { candidates = input.flatMap { candidate => resolveAsColumn(nameParts, resolver, candidate) } } def name UnresolvedAttribute (nameParts).name candidates.distinct match { case Seq ((a, Nil )) => Some (a) case Seq ((a, nestedFields)) => try { val fieldExprs = nestedFields.foldLeft(a: Expression )((expr, fieldName) => ExtractValue (expr, Literal (fieldName), resolver)) val aliasName = nestedFields.last Some (Alias (fieldExprs, aliasName)()) } catch { case a: AnalysisException if !throwErrors => None } case Seq () => logTrace(s"Could not find $name in ${input.mkString(", ")} " ) None case ambiguousReferences => val referenceNames = ambiguousReferences.map(_._1).mkString(", " ) throw new AnalysisException ( s"Reference '$name ' is ambiguous, could be: $referenceNames ." ) } } }
可见,LogicalPlan 比起 QueryPlan 扩展了 resolve 相关的操作,还加上了一个 statistics 变量。该变量实际上就是一个 BigInt,代表计划的执行代价,猜想在后续的执行计划优化过程中将会使用这个变量。
实现类 我们由浅到深地研究了三个核心类:LogicalPlan 、 QueryPlan 和 TreeNode,也学习了它们周边的一些核心类,如 Expression 、 Attribute 等。但以上的这些类都有一个特点:它们都是虚类,我们至今没有见到一个 concrete 的类。同时,早在 TreeNode 就已经有使用 productIterator 等 Product 特质的方法,但直到 LogicalPlan 都仍然把混入 Product 特质的工作交给子类,我们仍然不知道 Product 的元素究竟意味着什么。
现在我们就先来看看 LogicalPlan 的子类。实际上就在 LogicalPlan.scala 中我们就能看到三个 LogicalPlan 的子类:
1 2 3 4 5 6 7 8 9 10 11 abstract class LeafNode extends LogicalPlan with trees .LeafNode [LogicalPlan ] self: Product => } abstract class UnaryNode extends LogicalPlan with trees .UnaryNode [LogicalPlan ] self: Product => } abstract class BinaryNode extends LogicalPlan with trees .BinaryNode [LogicalPlan ] self: Product => }
但暂时来讲并没有什么用,这三个类也是虚类,依然没有混入 Product 特质,甚至什么方法都没有实现。我们随便抓一个他们的子类:
1 2 3 case class Intersect (left: LogicalPlan , right: LogicalPlan ) extends BinaryNode override def output Seq [Attribute ] = left.output }
这下就真相大白了。所有的这些虚类的实现类都是 Scala 的 case class,而 Scala 的样例类都会自动实现 Product 特质,并以 case class 的数据成员作为 Product 的元素。现在你再回到之前的三个核心类中去看那些调用了 productIterator 的方法你就能理解了。
总结 在这篇文章中,我们学习了以 LogicalPlan 类为核心的执行计划树数据结构。下一次我们将开始讲解 Analyzer 的相关代码,敬请期待。