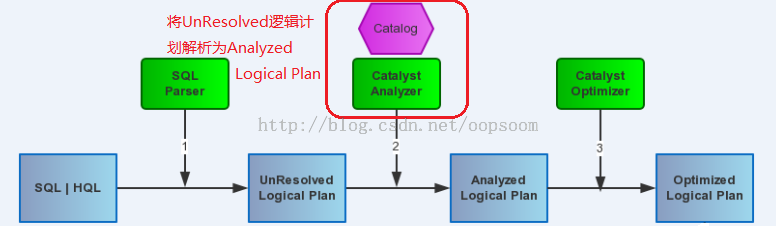
/** * Provides a logical query plan analyzer, which translates [[UnresolvedAttribute]]s and * [[UnresolvedRelation]]s into fully typed objects using information in a schema [[Catalog]] and * a [[FunctionRegistry]]. */ classAnalyzer( catalog: Catalog, registry: FunctionRegistry, conf: CatalystConf, maxIterations: Int = 100) extendsRuleExecutor[LogicalPlan] withHiveTypeCoercionwithCheckAnalysis {
// ...
val fixedPoint = FixedPoint(maxIterations)
/** * Override to provide additional rules for the "Resolution" batch. */ val extendedResolutionRules: Seq[Rule[LogicalPlan]] = Nil
// 在传入的 plan 上迭代地执行由子类定义的 batch defexecute(plan: TreeType): TreeType = { var curPlan = plan
batches.foreach { batch => val batchStartPlan = curPlan var iteration = 1 var lastPlan = curPlan varcontinue = true
// Run until fix point (or the max number of iterations as specified in the strategy. while (continue) { // 对 curPlan 顺序执行一次当前 batch 的所有 rule curPlan = batch.rules.foldLeft(curPlan) { case (plan, rule) => val result = rule(plan) if (!result.fastEquals(plan)) { logTrace( s""" |=== Applying Rule ${rule.ruleName} === |${sideBySide(plan.treeString, result.treeString).mkString("\n")} """.stripMargin) }
result } iteration += 1 // 根据最大迭代数或是否达到不动点来确定是否要继续迭代 if (iteration > batch.strategy.maxIterations) { // Only log if this is a rule that is supposed to run more than once. if (iteration != 2) { logInfo(s"Max iterations (${iteration - 1}) reached for batch ${batch.name}") } continue = false } if (curPlan.fastEquals(lastPlan)) { logTrace( s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.") continue = false } lastPlan = curPlan // 进入下一轮迭代 }
if (!batchStartPlan.fastEquals(curPlan)) { logDebug( s""" |=== Result of Batch ${batch.name} === |${sideBySide(plan.treeString, curPlan.treeString).mkString("\n")} """.stripMargin) } else { logTrace(s"Batch ${batch.name} has no effect.") } // 进入下一个 batch }