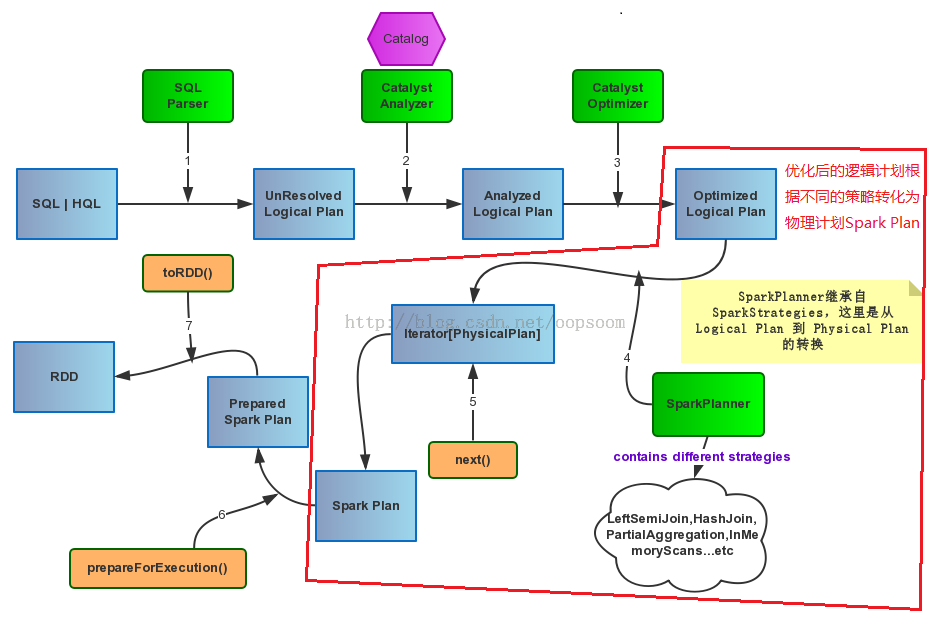
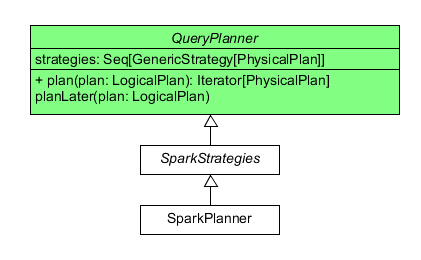
// 相对的,QueryPlanner 也和 RuleExecutor 十分相似 abstractclassQueryPlanner[PhysicalPlan <: TreeNode[PhysicalPlan]] { /** A list of execution strategies that can be used by the planner */ defstrategies: Seq[GenericStrategy[PhysicalPlan]]
defplan(plan: LogicalPlan): Iterator[PhysicalPlan] = { // Lazy 地在 LogicalPlan 上 apply 所有 Strategy val iter = strategies.view.flatMap(_(plan)).toIterator assert(iter.hasNext, s"No plan for $plan") iter } }
// sqlContext will be null when we are being deserialized on the slaves. In this instance // the value of codegenEnabled will be set by the desserializer after the constructor has run. val codegenEnabled: Boolean = if (sqlContext != null) { sqlContext.conf.codegenEnabled } else { false }
/** Overridden make copy also propogates sqlContext to copied plan. */ overridedefmakeCopy(newArgs: Array[AnyRef]): this.type = { SparkPlan.currentContext.set(sqlContext) super.makeCopy(newArgs) }
// 先获得代表完整结果的 RDD val childRDD = execute().map(_.copy())
// result buffer val buf = newArrayBuffer[Row] // partition 总数 val totalParts = childRDD.partitions.length // 已扫描的 partition 数 var partsScanned = 0 while (buf.size < n && partsScanned < totalParts) { // 本次迭代尝试扫描的 partition 数 var numPartsToTry = 1 if (partsScanned > 0) { // 从第二次迭代开始 if (buf.size == 0) { // 如果第一次迭代完全没有获取到结果,直接扫描剩下所有 partition numPartsToTry = totalParts - 1 } else { // 1.5 * n / (buf.size / partsScanned) numPartsToTry = (1.5 * n * partsScanned / buf.size).toInt } } numPartsToTry = math.max(0, numPartsToTry) // guard against negative num of partitions
// 剩余所需结果数 val left = n - buf.size // 即将进行尝试的 partition 集 val p = partsScanned until math.min(partsScanned + numPartsToTry, totalParts) val sc = sqlContext.sparkContext val res = sc.runJob(childRDD, (it: Iterator[Row]) => it.take(left).toArray, p, allowLocal = false)
defplan(plan: LogicalPlan): Iterator[PhysicalPlan] = { // Lazy 地在 LogicalPlan 上 apply 所有 Strategy val iter = strategies.view.flatMap(_(plan)).toIterator assert(iter.hasNext, s"No plan for $plan") iter } }
plan 函数的 iter = strategies.view.flatMap(_(plan)).toIterator 这句是不是有点问题?为什么 planLater 那个实现返回的是一个占位符?这个问题我们先不着急回答,我们先看看 Strategy 实现类是怎么使用 planLater 的: